

DASCHOOL 할인 리턴즈
[정보TALK] 이상치 판단 기준이 실무에서도 같을까요?
안녕하세요 :) ‘분데데분’입니다.
분석을 하면 이상치를 자주보게 되는데요!
어서 처리해야할 것만 같은 기분이 듭니다.
IQR! 박스플롯! = 이상치 처리!
과연 현업에서도 이상치 처리를 위해 위와 같은 방법으로 처리할까요?
.
.
.
먼저, 여러분들은 이상치에 대해 어떻게 생각하나요?
“이상치는 데이터 패턴에서 튄 값이야!”
‘흐음.. 분명 틀린 말은 아닌데.. 뭔가 부족한 느낌이 든단 말이지..’
그럼 이번 시간에 ‘이상치’에 대해 한번 알아볼까요?

‘본 포스팅은 데이콘 서포터즈 ‘데이크루 1기’활동의 일환입니다.’
[이상치(Outlier)]
이상치는 무엇일까요? (Lee Sang Chi)
위 그래프에서 이상치를 찾으라고 하면 대부분 저렇게 표시를 할 거예요. 저 또한 그럴겁니다.
그럼 이렇게 이해하면 되겠네요.
이상치는 '보통 관측된 데이터의 범위에서 많이 벗어난 아주 작은 값이나 큰 값'
통계학에서는 이렇게 정의합니다. '변수의 분포상 비정상적으로 극단적인 값을 가져 일반적으로 생각할 수 있는 범위를 벗어난 관측치'
[이상치 원인]
그럼, 이상치는 왜 생기는 걸까요?
데이터 수집 중 타이핑 실수, 비정상적인 측정 등이 존재하는데요. 정리해봅시다.
[이상치 탐지 방법]
이상치는 어떻게 찾아내는지 알아보자구요!
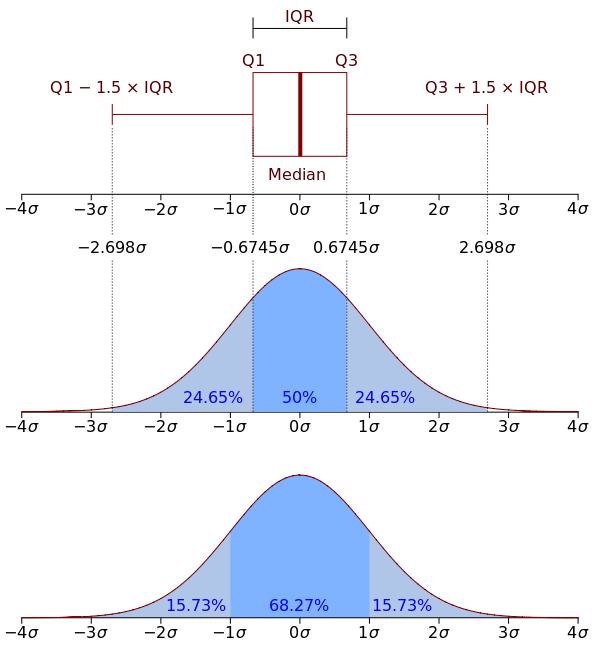
여기서 Q1 - 1.5 * IQR 이하, Q3 +1.5 * IQR 이상인 경우 보통 이상치로 판단합니다.

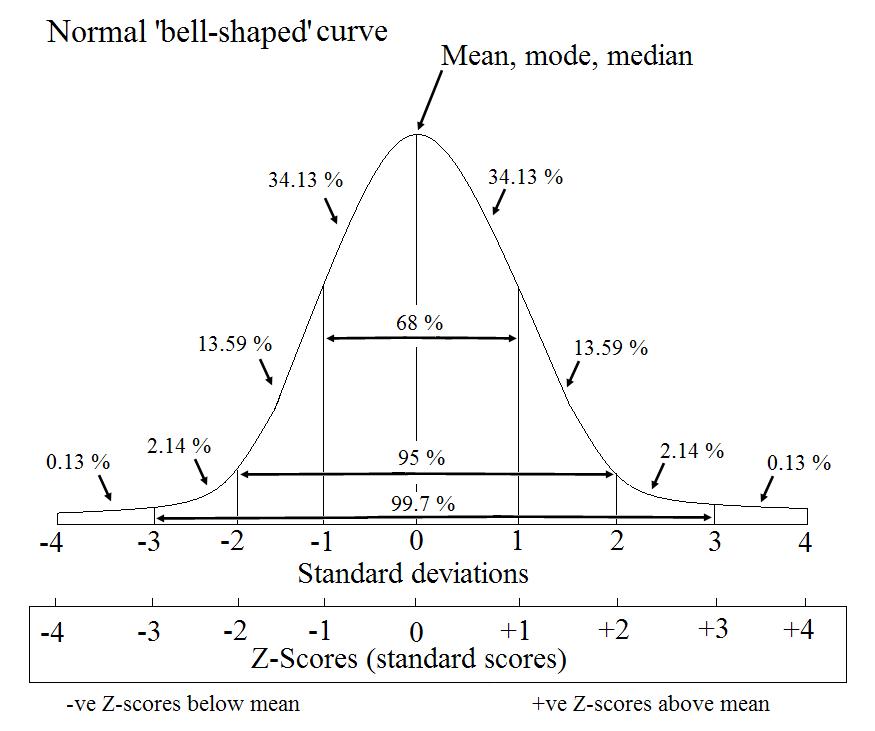
표준 점수(Standard Score)로 불리우며, 정규분포를 만들고 각 데이터가 표준편차를 기준으로 어떤 위치에 존재하는지 보여주는 수치입니다.
윗 그림처럼 1.8 이상 -1.8 이하 값에 속한 값들을 이상치로 정의하죠. (2.0으로 쓰는 경우도 존재합니다)
이외에도 마할라노비스 거리(Mahalanobis Distance), DBSCAN 등이 존재하지만, 본 글의 초점이 아니니 여기까지만 설명하려 합니다.
[이상치에 대한 고찰]
자, 이상치의 개념과 탐지 방법에 대해 알아보았는데, 우리는 ML 모델이 잘 예측할 수 있도록 이상치를 처리할 필요가 있습니다.

“이상치니까 행을 지우거나, 통계값 대체하거나 해야겠다”
잠깐! 처리하기전에 잠시 생각을 해보자구요!
자격 검정에는 위와 같은 방법으로 이상치를 탐지하고, 처리하는 방법을 제안합니다.
단순분석인 경우에도 적용되구요.
이상치.. 실무에서는 어떨까요?
데이터들이 정규분포가 아닌 경우가 존재하고, *3sigma가 도메인에서는 의미가 없는 경우들이 존재합니다. 가끔 3sigma의 바깥 데이터만을 가지고 뭔가 해야하는 경우가 있기도 하구요.
*3sigma : 정규분포내에서 어떤 데이터가 +-3sigma밖에 존재할 확률은 0.3%이기 때문에 이 범위를 벗어나면 이상치로 판단
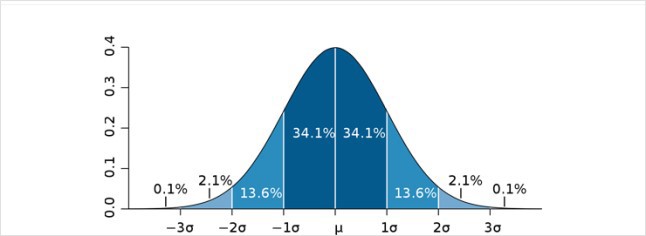
그래서 자격 시험과 실무에서 이상치를 바라보는 것은 다른 것을 이해해야합니다. 도메인 관점에서 본다면, 말이 안되는 숫자이기도 한데, 의도와 과정이 맞다면 맞는 데이터일 가능성이 큽니다.
그럼, 도메인 논문을 참조해서 이상치를 정하면 될까요?
같은 분야라도 Case by Case 가 존재하고, 낯선 도메인 논문을 보고 알아내기도 어렵습니다. 그래서 분석 의뢰자에게 물어봅니다.
“이렇게 처리했는데 괜찮은가요?”라고 말한 후 분석하고 도무지 판단 기준이 서지 않을 때 이메일이나 전화로 물어봅니다.
데이터가 이렇게 주어져 있는데 왜 이러는지를 말이죠.
오늘은 ‘이상치’에 대해 다루어보았습니다.
행을 삭제한다든지, 통계값을 대체한다든지 어떻게든 이상치를 처리하려고 했던 제 모습이 떠오릅니다.
그러나 이상치가 무엇을 뜻하는지에 대해 생각을 해보지 못했네요.
이젠 생각이 바뀌었습니다.
.
.
.
‘이상치는 이상치일 뿐, 쓸모없는 데이터가 아니다’
글을 마치도록 하겠습니다. 감사합니다.
-
reference
https://medium.com/@Aaron__Kim/outlier-모두-제거해야할까-3aec52ef21b1
https://ourcstory.tistory.com/142
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=qbxlvnf11&logNo=221453279217
DACON Co.,Ltd | CEO Kookjin Kim | 699-81-01021
Mail-order-sales Registration Number: 2021-서울영등포-1704
Business Providing Employment Information Number: J1204020250004
#901, Eunhaeng-ro 3, Yeongdeungpo-gu, Seoul 07237
E-mail dacon@dacon.io |
Tel. 070-4102-0545
Copyright ⓒ DACON Inc. All rights reserved

 List
List