

DASCHOOL 할인 리턴즈
[정보TALK] 모델 평가(1)
안녕하세요! '분데데분'입니다.
이번 글은 '모델 평가'에 대해 작성해보려 합니다.
'본 포스팅은 데이콘 서포터즈 '데이크루 1기' 활동의 일환입니다.'
먼저, 왜 우리는 예측 모델을 만드는 걸까요?
높은 성능을 가진 모델로 '어떤 데이터'를 예측하기 위해서입니다. 이러한 예측 능력을 '일반화 성능'이라고 부르죠.
보통 train set을 train set과 valid set로 다시 나누고, valid set 예측 성능을 평가지표에 반영한 점수로 평가하는데요.
여기서 데이터를 적절히 나누고 일반화 성능을 평가하는 작업 자체를 '검증'이라고 부릅니다.
홀드아웃 검증

train set의 일부를 학습에 사용하지 않고 valid set으로 남겨둡니다. train set으로 모델 학습시키고, 남겨둔 valid set 데이터로 모델을 평가합니다. 이후 test set을 예측하죠.
#sklearn.model_selection import train_test_split을 사용하거나,
#sklearn.model_selection import KFold 클래스로 여러 차례 분할 한 것 중 하나를 사용해서 train set, valid set으로 나눌 수 있습니다.
단, 홀드아웃 검증은 train set과 test set 데이터들이 무작위로 분할 되었다는 전제 하에 성립되는 방법입니다.
종종 데이터가 어떤 규칙에 따라서 나열된 경우에는 데이터를 섞어야 합니다.
이때 "첫 행부터 어느 행까지 train set, 나머지는 valid set으로 지정해야지~!"
이런 식으로 분할하면 올바른 학습 및 평가를 하기 어렵습니다.
다른 검증방법에서도 마찬가지인데, 무작위로 데이터가 있는 것처럼 보여도 데이터를 Shuffle 하는 것이 좋습니다.
#train_test_split(shuffle=True)
그럼, 홀드아웃 검증은 강력한 검증 방법이라고 이야기 할 수 있을까요?
홀드아웃 검증은 데이터를 효율적으로 사용하지 못한다는 단점이 있습니다.
valid set 데이터가 적으면 평가를 신뢰하기 어려운데, valid set을 늘리면 train set 데이터가 줄어들어 예측 성능이 떨어집니다.
물론 test set 데이터를 예측할 때 train set 데이터 전체에서 모델을 다시 구축할 수 있는데, 학습 시의 모델과 최종 모델의 데이터 수가 다르면 최적의 hyperparameter이나 특징이 달라질 수 있으므로, 검증에서도 train set은 어느 정도 확보하는 편이 바람직합니다.
교차 검증
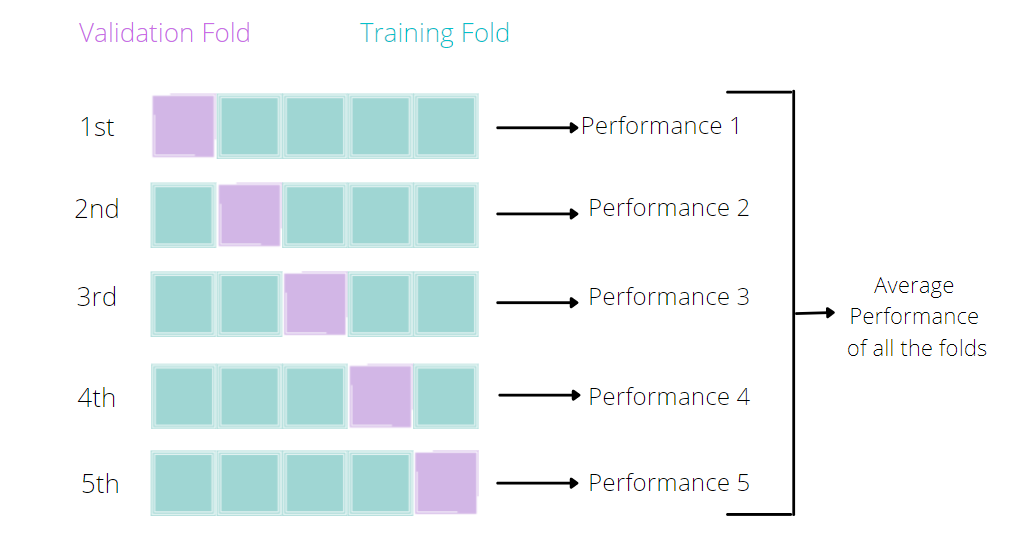
train set을 분할하고 홀드아웃 검증 방법을 여러 번 반복하고 매 회 검증 학습에 이용할 데이터의 양을 유지하면서도 검증 평가에 필요한 데이터를 train set 데이터 전체를 할 수 있습니다. 이 검증 방법을 '교차 검증' 이라고 부르며 많이 사용되고 있습니다.
#from sklearn.model_selection import KFold
교차 검증의 폴드 수는 n_splits 인수로 지정합니다.
fold 수를 늘릴수록 train set 데이터의 양을 더 확보할 수 있으므로 데이터 전체로 학습시켰을 때와 유사한 모델 성능으로 평가할 수 있습니다.
단, 연산 시간이 늘어나므로 *Trade off 됩니다.
fold수를 2에서 4로 늘리면 연산 횟수는 두 배가 되는데, train set 데이터는 전체의 50%에서 75%로 1.5배 증가 됩니다.
train set 데이터가 1.5배가 증가하면 성능이 개선을 기대해볼 수 있습니다.
교차 검증에서 알아두어야 할 세 가지가 있습니다.
하나, 교차 검증의 fold수를 늘린다고만 해서 연산 시간에 비해서 실제 개선으로 바로 이어지지는 않습니다. 대회에서는 주로 fold 수를 4 또는 5로 설정하곤 합니다.
최적의 fold 수를 위해 연산 시간과 train set 데이터의 비율, validation 점수의 관계를 살펴보아야 합니다.
둘, 주어진 train set 데이터가 충분히 큰 상황에서 검증에 이용하는 train set 데이터의 비율을 변경해도 모델의 성능이 거의 변하지 않는 경우도 있습니다.
이렇게 데이터가 큰 경우 fold 수를 2~3으로 하거나, 앞서 말한 홀드아웃 검증 방법을 선택해볼 수 있습니다.
셋, 평가지표에 따라서는 각 fold의 점수의 평균과, 데이터 전체에서 target과 prediction 연산 점수가 서로 일치하지 않습니다.
MAE 또는 log loss에서는 일치하는데, RMSE에서는 각 fold 점수의 평균이 데이터 전체로 연산한 결과보다 낮아집니다.
이외에도 검증에는 층화 K-겹 검증, 그룹 K-겹 검증 등이 존재합니다.
그럼, 시계열 데이터에서도 적용이 될까요?
.
.
.
다음 글, 모델 평가(2), 시계열 데이터 모델 평가로 찾아오겠습니다. 감사합니다 :)
*Trade off : 증가가 있다면, 어느 한 부분에는 감소가 있는 것
-
reference
감사합니다, 월드파파님!
DACON Co.,Ltd | CEO Kookjin Kim | 699-81-01021
Mail-order-sales Registration Number: 2021-서울영등포-1704
Business Providing Employment Information Number: J1204020250004
#901, Eunhaeng-ro 3, Yeongdeungpo-gu, Seoul 07237
E-mail dacon@dacon.io |
Tel. 070-4102-0545
Copyright ⓒ DACON Co.,Ltd All rights reserved
 List
List
처음 검증 과정을 공부하였을 때 많이 헷갈렸었는데 알기 쉽게 정리해주셔서 감사합니다~