

DASCHOOL 할인 리턴즈
머신러닝 군집화 GMM(Gaussian Mixed Model)
안녕하세요.
데이크루 1기로 활동 중인 '동화책'입니다. 🤓📚
오늘은 머신러닝의 군집화 기법 중 GMM에 대한 설명을 가지고 와보았습니다.
K-평균(K-Means)이나 평균 이동(Mean Shift)에 비해서 덜 알려진 방법인데 데이터의 분포를 여러개의 가우시안 분포로 가정하면 잘 작동될 수 있는 알고리즘입니다.
참고 자료
여러 개의 정규분포를 이루는 데이터가 합쳐진 집합(모집단)에서 데이터가 추출된 것(표본)이라는 가정하에 군집화를 수행하는 알고리즘
GMM에서의 모수 추정 : 1. 개별 정규 분포의 평균과 분산 2. 각 데이터가 어떤 정규 분포에 해당하는지의 확률
1. MLE 정의
모수적(parametic)인 밀도 추정 방법으로 파라미터 θ=(θ1,⋯,θm) 으로 구성된 어떤 확률 밀도함수 P(x|θ) 에서 관측된 표본 데이터 집합을 x=(x1,x2,⋯,xn) 이 표본들에서 파라미터 θ=(θ1,⋯,θm) 를 추정하는 방법
(예) 아래의 그림에서 관측된 데이터는 파란색 곡선보다 주황색 곡선으로부터 추출된 가능성이 더 커보인다. 데이터를 통해서 주황색 곡선의 평균과 분산을 구하는 것이 MLE의 목표이다.
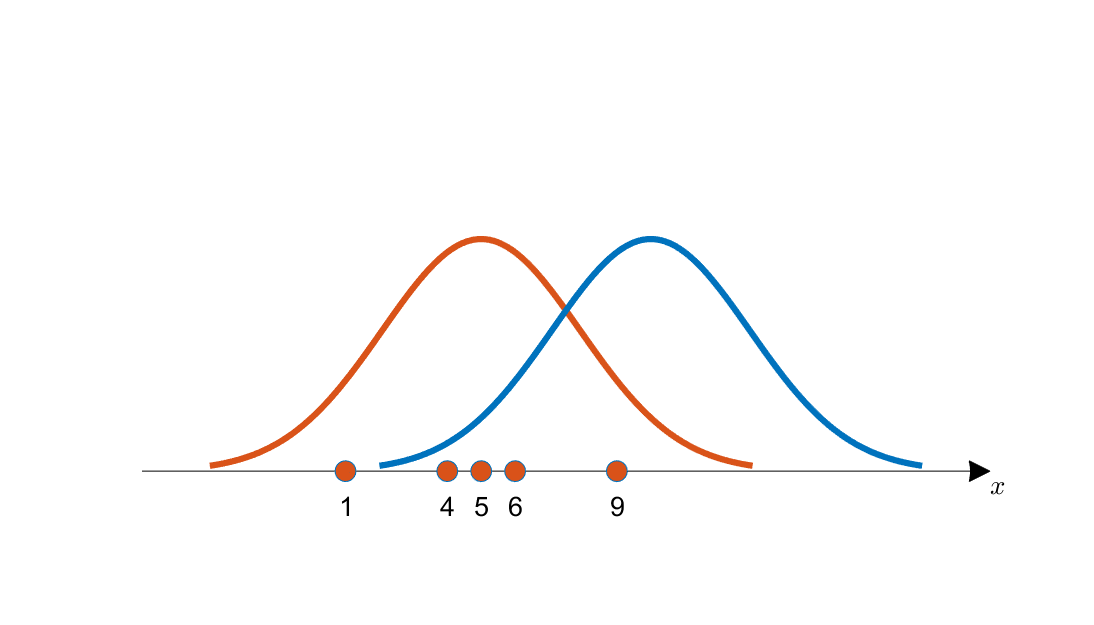
[출처:공돌이의 수학정리노트]
2. 결합 확률 밀도 함수(Likelihood Function)
cf. 높이를 더하지 않고 곱하는 이유는 모든 데이터 추출이 독립적으로 일어나는 사건이기 때문이다.


3. 결합 확률 밀도 함수에서 최댓값을 찾는 방법
- 계산의 편의를 위해 로그-결합 확률 밀도 함수를 사용하고 편미분함수=0을 이용한다.

4. 모평균, 모분산 추정
MLE을 통해 증명이 가능하다. 아래의 조건식을 만족할 때 결합 확률 밀도 함수가 최대가 된다.
- 모평균 :

- 모분산 :

5. 넘어가기 전에
수직선 상에 데이터가 10개 주어져있고, 각 데이터에 label이 주어져있다고 가정해보자.
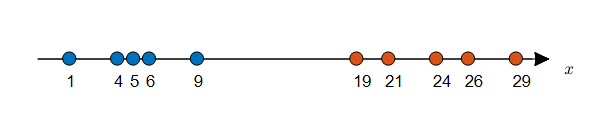
[출처:공돌이의 수학정리노트]
MLE 방식을 통해 각 클래스에 따른 모평균, 모분산 추정을 통해 확률 분포를 알아낼 수 있다.

[출처:공돌이의 수학정리노트]
하지만 label이 주어지지 않는다면? 모평균과 모분산 추정이 불가능하다. → EM 사용
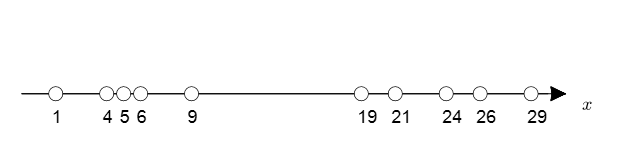
[출처:공돌이의 수학정리노트]
데이터에 label이 주어지지 않을 경우 데이터가 정규 분포를 이루는 데이터 집합(모집단)으로부터 추출되었다고 가정하고 군집화를 수행하는 알고리즘 = GMM(Gaussian Mixture Model)
작동 과정
1. 각 클래스별로 임의의 모수 (μ,σ)
을 지정하고 각 클래스에 대한 분포를 알아낸다.
2. 각 클래스에 따른 분포가 주어지면, 각 데이터에 대한 분포의 함수값(높이, 가능도, Likelihood)를 비교하여 각 데이터에 라벨링을 해준다.
3. 동일한 라벨링을 한 군집을 묶어 평균과 표준편차를 계산하고, 새로운 분포를 바탕으로 새로운 라벨링을 수행한다.
class sklearn.mixture.GaussianMixture(n_components=1, *, covariance_type='full', tol=0.001, reg_covar=1e-06, max_iter=100, n_init=1, init_params='kmeans', weights_init=None, means_init=None, precisions_init=None, random_state=None, warm_start=False, verbose=0, verbose_interval=10)
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import make_blobs from sklearn.mixture import GaussianMixture # make dataset X, y = make_blobs(n_samples=300, n_features=2, centers=3, cluster_std=0.5, random_state=0) tf = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]] X_tf = np.dot(X, tf) df = pd.DataFrame(X_tf, columns=['ftr1','ftr2']) df['target'] = y # GMM gmm = GaussianMixture(n_components=3, random_state=0) df['gmm_label'] = gmm.fit_predict(X_tf) # plot visualize_cluster_plot(gmm, df, 'gmm_label', iscenter=False)
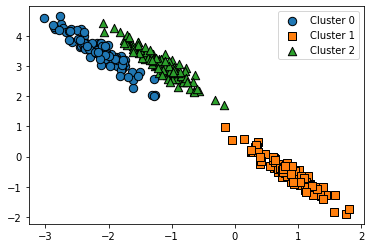
*본 포스팅은 데이콘 서포터즈 “데이크루" 1기 활동의 일환입니다.
DACON Co.,Ltd | CEO Kookjin Kim | 699-81-01021
Mail-order-sales Registration Number: 2021-서울영등포-1704
Business Providing Employment Information Number: J1204020250004
#901, Eunhaeng-ro 3, Yeongdeungpo-gu, Seoul 07237
E-mail dacon@dacon.io |
Tel. 070-4102-0545
Copyright ⓒ DACON Inc. All rights reserved
 List
List