

DASCHOOL 할인 리턴즈
[BASIC, TIP] 피처 스케일링이란? 정규화 vs 표준화?
피처 스케일링은 ML 성능을 좋게하기 위해 많은 분들이 시도하는 기법입니다! 정규화와 표준화가 헷갈린적이 많아서 관련 내용을 알아보던 중 좋은 글이 있어서 일부분 번역해서 정리해 보았습니다.
-------------------------------------------------------
✔️ 몇몇 머신러닝 알고리즘들은 피처 스케일링에 민감하기 때문입니다. 다음은 피처 스케일링에 민감한 알고리즘과 그렇지 않은 알고리즘에 대한 설명입니다.
➡️ 1. Gradient Descent Based Algorithms.

➡️ 2. Distance-Based Algorithms
➡️ 3. Tree-Based Algorithms
✔️ 정규화란 값들을 0과 1 사이의 범위로 이동하고 재조정시키는 스케일링 기법입니다. min-max scaling이라고도 합니다.

✔️ 표준화는 표준편차와 평균을 중심으로 하는 또다른 스케일링 기법입니다. 평균을 0으로 하고 결과 분포에 단위 표준편차를 사용합니다.
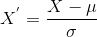
 는 평균,
는 평균, ✔️ 정규화는 데이터의 분포가 가우스 분포(Gaussian distribution)를 따르지 않을 때 사용하는 것이 좋습니다.(가우스 분포는 대부분 정규분포를 말합니다)
✔️ 표준화는 데이터가 가우스분포를 따를 때 유용할 수 있습니다.
✔️ scaler는 훈련 데이터셋에 fit한 이후에 테스트 데이터에 적용해야 합니다.
✔️ 위에서는 다루지 않았으나, 로그화와 정규화중에는 로그화를 먼저 진행하는 것이 좋다고 합니다.
✔️ 대부분의 스케일링 기법에서 이상치(outlier)는 변환 효과를 저해하기 때문에 이상치를 제거하려는 노력이 필요합니다. ( 평균과 분산으 이상치와 특이값이 굉장히 민감합니다.)
-------------------------------------------------------
이상으로 피처 스케일링에 대한 정리글을 마칩니다!
피처 스케일링에 대한 더 좋은 정보가 있다면 댓글로 알려주시면 좋겠습니다
감사합니다 😊
*본 포스팅은 데이콘 서포터즈 “데이크루" 1기 활동의 일환입니다. ✔️
DACON Co.,Ltd | CEO Kookjin Kim | 699-81-01021
Mail-order-sales Registration Number: 2021-서울영등포-1704
Business Providing Employment Information Number: J1204020250004
#901, Eunhaeng-ro 3, Yeongdeungpo-gu, Seoul 07237
E-mail dacon@dacon.io |
Tel. 070-4102-0545
Copyright ⓒ DACON Inc. All rights reserved
 List
List