

DASCHOOL 할인 리턴즈
자율주행 센서의 안테나 성능 예측 AI 경진대회
train_test_split 으로 구한 score 랑 제출 점수랑 많이 차이나는데 원래 그런가요?
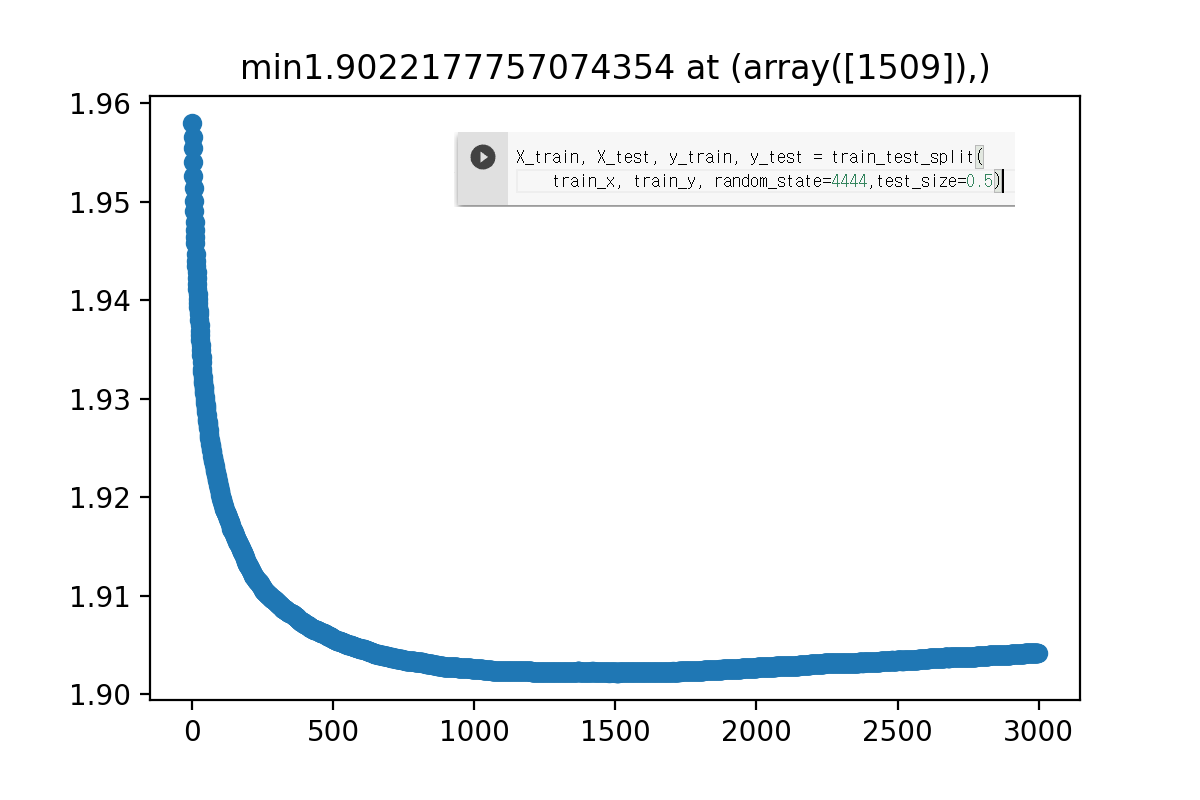
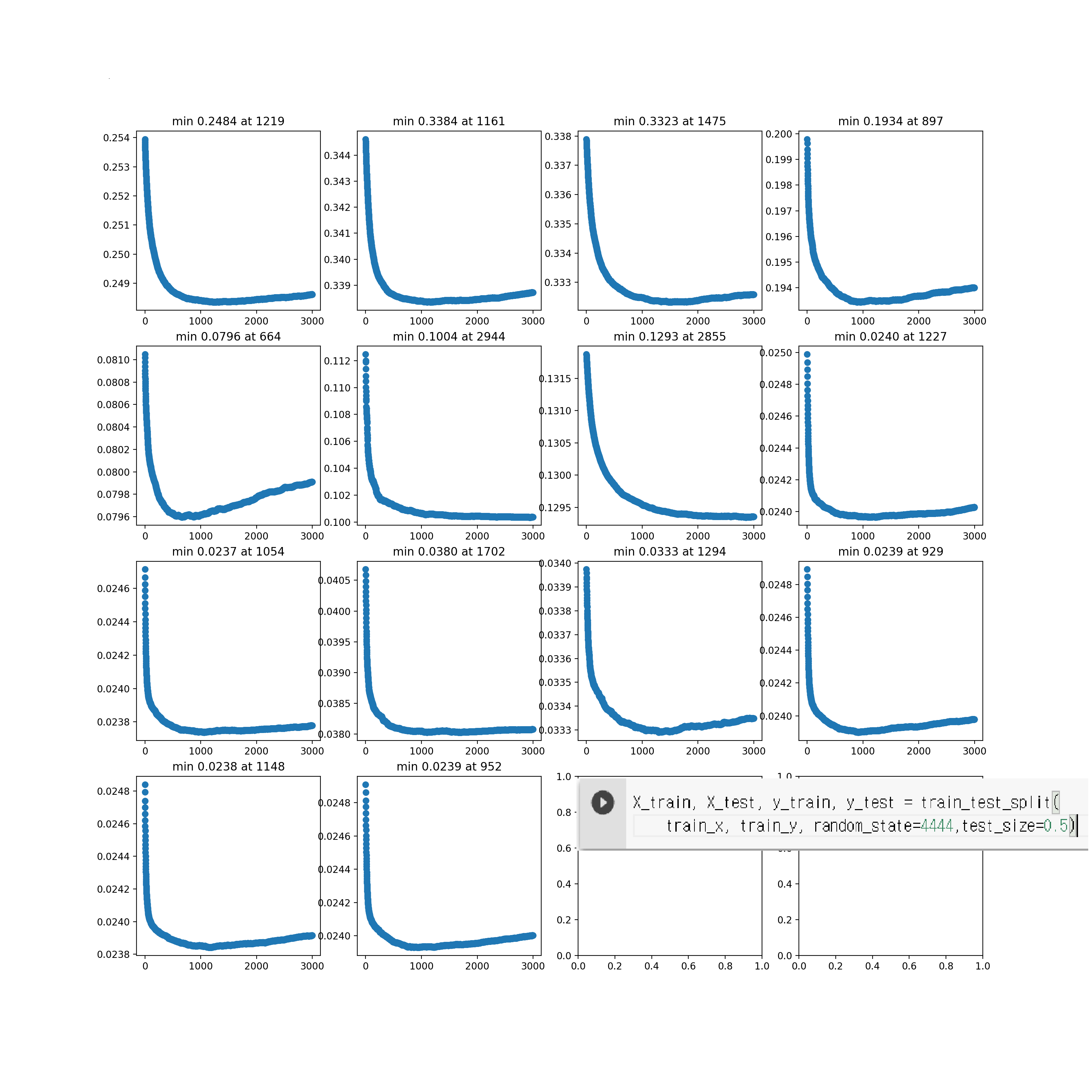
test size 0.5 일때
test size 0.1 일때
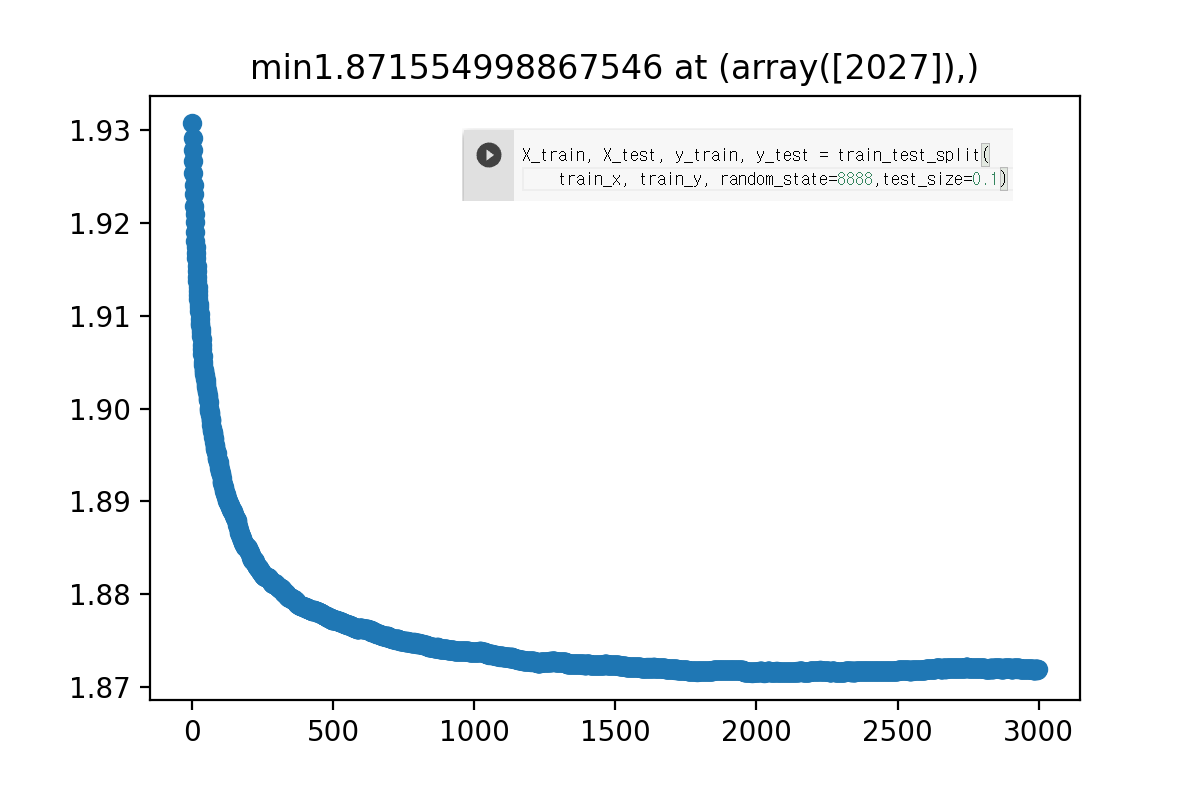
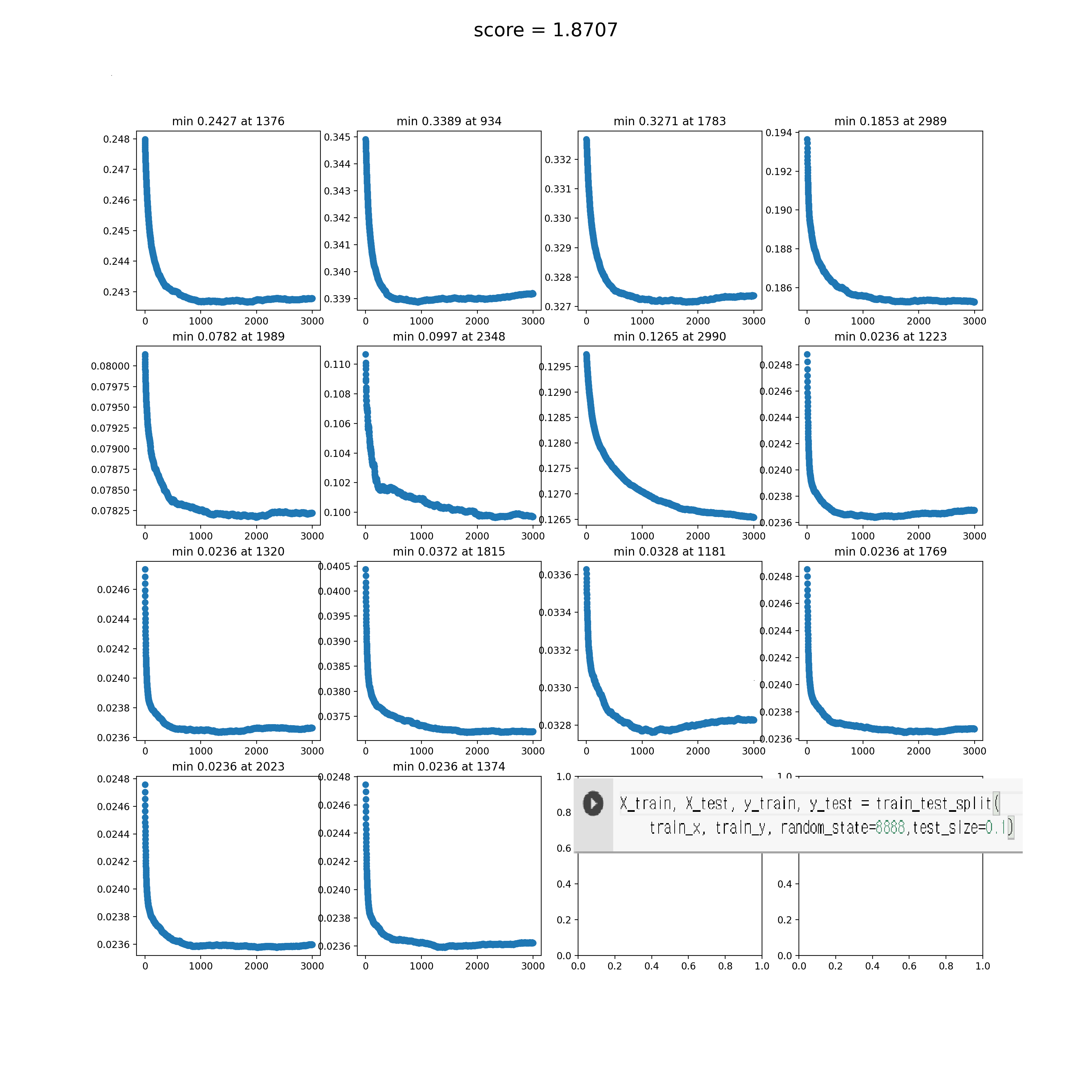
시드 바꾸면서 몇번 해 봐도 트레이닝 셋을 분할했을때는 점수가 비슷한데 리더보드 점수는 확 안좋게 나오네요
트레이닝 데이터랑 테스트 데이터의 분포가 다른걸까요?
대충 베이스라인 잡는다고 다때려넣고 모델끼리 평균낸게 트레이닝 셋에서 검증할땐 1.97 정도 나왔는데
리더보드 에 올리니 1.94정도로 더 좋게 나와서 당황스럽네요
배우기 시작한지 얼마안된 초보라 고수님들 의견이 듣고싶네요
DACON Co.,Ltd | CEO Kookjin Kim | 699-81-01021
Mail-order-sales Registration Number: 2021-서울영등포-1704
Business Providing Employment Information Number: J1204020250004
#901, Eunhaeng-ro 3, Yeongdeungpo-gu, Seoul 07237
E-mail dacon@dacon.io |
Tel. 070-4102-0545
Copyright ⓒ DACON Co.,Ltd All rights reserved
 List
List
트레이닝 데이터와 테스트 데이터의 분포가 같다는 법은 없습니다. 프라이빗 데이터의 분포는 또 다를 수도 있죠.
트레이닝 데이터에서 점수를 올렸는데 테스트 데이터에서 오히려 점수가 떨어졌다면 트레이닝 데이터에 과적합
(Overfitting) 되었다고 보고 과적합을 해결해야겠죠.
다만 train_test_split을 사용했다면 트래이닝 데이터를 전부 사용한게 아니라 일부만 학습에 사용하면서 분포가
더 달라졌을 수 있습니다. k-fold 등의 방법으로 트레이닝 데이터 전체를 사용하면 분포 차이가 조금 더 해결될 수 있습니다.