

DASCHOOL 할인 리턴즈
재정정보 생성 AI 활용 검색 알고리즘 경진대회
이런건 도대체 어떻게 해야할까요?

test 8번 질문은 "혁신창업사업화자금(융자) 사업 집행절차는 어떻게 되나요?"이고, soruce는 중소벤처기업부_혁신창업사업화자금(융자).pdf의 위 사업진행절차를 근거로 대답해야합니다
문제는 저걸 텍스트로 끌고오면 대략 이렇게 되는데요

이게 안타깝게도 왼쪽부터 오른쪽으로 보통 읽으니 모델은 저 기호를 잘 이해못하고(원본이 어떻게 생긴지 정확히 모르니) 융자실행이 4번째 순서라고 아는것같습니다
저는 실제로 이렇게 답변이 나오는데요
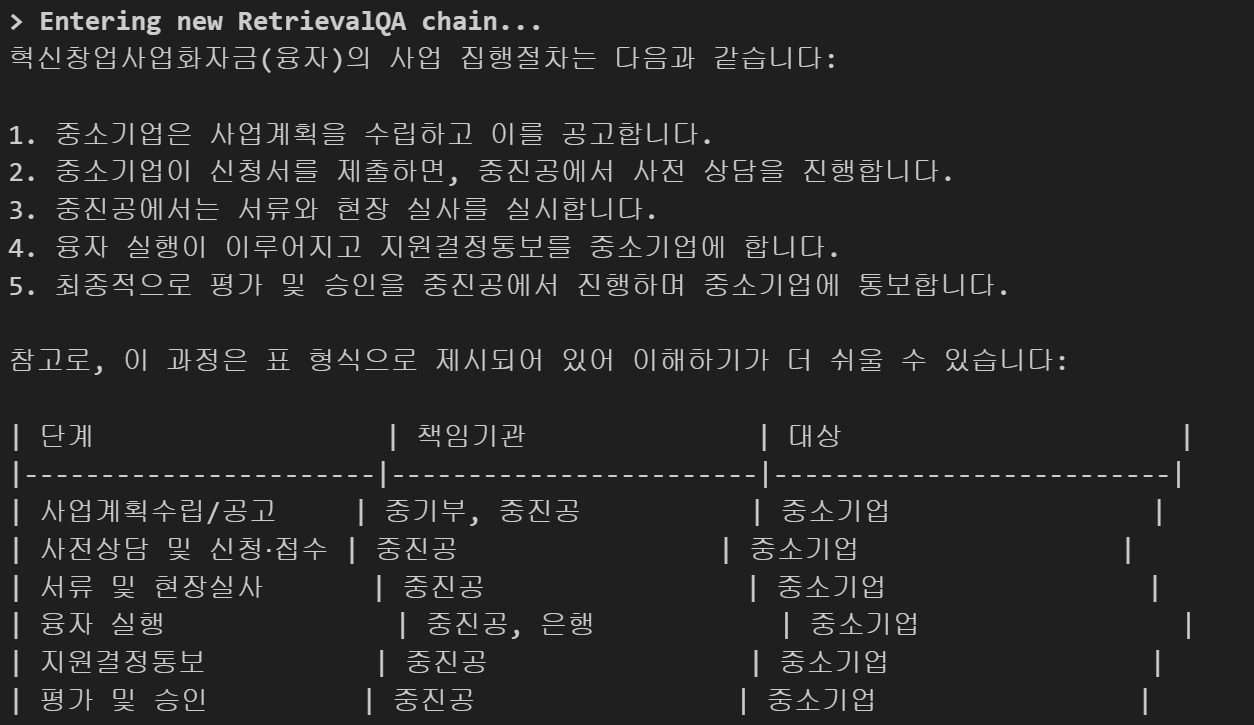
저런 공문도 사실 a4 용지에 맞추다보니까 어쩔수없이 3번에서 4번으로 넘어갈 때 저런 아랫기호를 써서 "인간"관점에선 가독성을 높이는데,(만약에 서류및 현장실사 -> 융자실행을 바로 가게 하고 싶으면 대각선을 긋던가, 아니면 다르게 자료를 만들어야하니) "AI" 관점에선 가독성이 떨어집니다
참 웃기죠? 챗봇 AI가 인간을 위해 존재하는데, 역설적으로 인간에게 잘 보이는 자료가 챗봇AI에게는 잘 안보이는 자료라는게...
이런 세상이 올까요? 우리가 만드는 자료들을 챗봇AI가 더 잘 이해하게 만들되 특히 사람들이 덜 이해할 수도 있을수도 있는 자료를 만드는 세상이요...
하지만 최종적으로 그럼으로써 챗봇이 더 잘 이해할 수 있으니까 인간이 일시적으로 불편함을 겪되 결국 챗봇 성능이 좋아질테니 인간이 오히려 희생하는... 그런... 날이 과연 올까요?
어떻게하면 융자실행이 마지막 순서에 나오게할 수 있을까요? 좋은 랭기지 모델은 가능할련지... 로컬에서 꾸역꾸역 짜내서 답낸거라 전 일단 저렇게 나오는데, 글쌔요 저런 기호까지 잘 처리하는 랭기지모델이 있나요?? 파인 튜닝 영역도 아닌 것 같고...
대회 첫날이지만 약간은 여러 생각이 드네요
모쪼록 다들 화이팅입니다..!
답변 순서와 같은 부분은 2차 평가인 전문가 평가 점수에서 차이가 나지 않을 까 생각됩니다. 100점 중 40점입니다
나중에 코드공유에 좋은 인사이트가 나오면 좋겠네요 ㅎㅎ 댓글 감사합니다
다만 참고로 말씀드리면, 이 이슈 관련하여 저는 입상권 목표로 하고 있지 않아서 크게 상관은 없는데 입상권 목표하시는 분은 다음 참고하시면 되겠습니다 :
저런 특정 표에 대해서 예외처리하는 방법도 생각할 수 있으나 test set의 특정 데이터 양식을 "예견"하고 전처리 하고 rag를 하는 경우는 일종의 data leakage가 될 수 있으니 주의하셔야할 듯 합니다. 물론 train set에서 저런 유사 양식이 나오는 게 확인이되고, train set에서 해결하는 로직을 짠 다음에, pred를 하는 경우는 괜찮을 것으로 보입니다. 하지만, 특정 test set의 pdf에서, 그 test pdf에서만 단독으로 발견가능한(train set엔 없는) 어떤 사안을 test q&a를 맞추기 위해 처리하는건 data leakage로 나중에 코드리뷰때 이슈가 될 수 있습니다.
보통 data leakage가 test set을 학습 시킨뒤 파라미터를 뽑아오는게 주 이슈긴한데(test set에 맞춰서 배치사이즈나 temperature를 조절하는 경우) 이번 대회는 이러한 전처리 또한 test set을 아예 못본다 가정해야하므로, test set에 맞춰서 전처리하는 것도 data leakage로 보입니다
저번 한솔데코 대회의 경우, 데이터가 완전히 텍스트로만 제시되어서 이런 이슈가 크게 없었는데, 이번엔 텍스트와 표가 혼합되어 있어서 더 주의하셔서 입상권 노리시는분들은 참고하셔서 하셔야할 듯 합니다 물론 저보단 잘 아시겠지만요... 또 제 의견일뿐 data leakage가 아닐 수도 있으니 재확인하시면 되겠습니다
모쪼록 한국어 llm 대회는 귀한 만큼, 좋은 인사이트가 나오길 기대합니다...!
그리고 노파심에 하나 더 말씀드리면, 혹시나 유료 api(gpt4 claude 등등)로 call 해서 pred 하신다음 데이콘에 제출했는데 점수가 비정상적이게 높으면 실격처리될 수도 있을 것 같으니 조심하시길 바랍니다....!
예전에 공공데이터 관련해서 열린 데이콘 대회에서 test set 정답지가 인터넷에 잘 찾아보면 어디 나와있는 대회가 있었는데, 어떤 분이 그거 그대로 써서 올렸다가 public 기간에 실격처리된게 기억이 나네요 또 예전 krx 대회에선 샤프지수 지나치게 높게 나오면(그것또한 과거 주가지수가 test set이었기때문) 코드 조기 제출하라고 했던 전례도 있으니, 입상권 노리시면 조심하시길 바라겠습니다..
근데 분명히 리더보드상엔 유료 api로 돌려서 제출하신 분도 있을 것 같은데, 막 높을 거라 기대되진 않네요. 보수적으로는 코드 공유에 올라온 자체 f1 스코어 코드사용하여 참고용으로만 쓰시는게 좋을 듯 합니다
DACON Co.,Ltd | CEO Kookjin Kim | 699-81-01021
Mail-order-sales Registration Number: 2021-서울영등포-1704
Business Providing Employment Information Number: J1204020250004
#901, Eunhaeng-ro 3, Yeongdeungpo-gu, Seoul 07237
E-mail dacon@dacon.io |
Tel. 070-4102-0545
Copyright ⓒ DACON Inc. All rights reserved
 List
List
근데 한편으로는 채점할 때 저것도 고려를 할 지도 궁금하네요 지금 1-2-3-4-5-6의 순서가 1-2-3-6-5-4로 대답을 한건데, 사실, 채점 측면에선 코싸인 유사도나 혹은 w2vec이든 등등 임베딩 순서를 고려한다하더라도, 사실은 3-6 에서만 감점먹지 나머지 5-4나 6-5로 역순으로 제시된건 또... 감점을 크게 안먹을 것 같기도 하네요 근데 융자집행이 먼저인지 아니면 나중에인지는 매우 현실에선 중요한건데, 채점에서도 이런게 잘 체킹이 되나 궁금하기도 합니다