

DASCHOOL 할인 리턴즈
AI Co-Scientist : 2025 Samsung AI Challenge
모델 크기 관련 문의입니다.
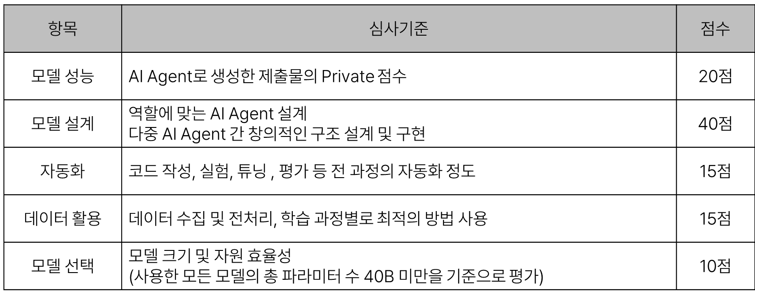
안녕하세요, 제출 파이프라인의 모델 파라미터 기준 관련하여 명확한 정의가 필요하여 질문드립니다.
이번 과제는 MCP (Multi-Component Pipeline) 및 A2A (Agent-to-Agent) 구조로 설계되어 있으며, 입력 유형에 따라 라우팅되어 서로 다른 모델 경로가 선택적으로 활성화되는 형태입니다.
→ 이처럼 각 task는 서로 다른 모델 경로를 사용하며, 모든 모델이 동시에 로드/사용되는 것이 아닙니다. 실제로는 입력에 따라 일부 모델만 활성화되는 구조입니다.
이런 구조에서 "총 파라미터 수"를 다음 중 어떤 기준으로 계산해야 하는지 명확한 지침이 필요합니다:
최근 LLM 활용에서 일반화된 양자화(quantization) 기법이 파라미터 수 기준과 충돌되는 사례가 있습니다:
→ 실제 자원 사용량(VRAM)이나 효율은 유사함에도 불구하고, 단순 파라미터 수 기준만 적용하면 전자가 불이익을 받게 됩니다.
torch.cuda.max_memory_allocated() 활용)
DACON Co.,Ltd | CEO Kookjin Kim | 699-81-01021
Mail-order-sales Registration Number: 2021-서울영등포-1704
Business Providing Employment Information Number: J1204020250004
#901, Eunhaeng-ro 3, Yeongdeungpo-gu, Seoul 07237
E-mail dacon@dacon.io |
Tel. 070-4102-0545
Copyright ⓒ DACON Inc. All rights reserved
 List
List
안녕하세요, mutoy님.
좋은 의견 주셔서 감사드립니다. 해당 내용은 주최측과 논의 후 안내드리도록 하겠습니다.
감사합니다.