

데이스쿨 할인 리턴즈
전이학습(Transfer Learning)이란?
안녕하세요.
데이크루 1기로 활동하고 있는 '동화책'입니다.📚🤓
오늘은 전이학습에 대한 이론 학습을 주제로 이야기를 해보려고 합니다.
지난주에 제가 '소규모 데이터셋으로 심층신경망 학습하기 (feat.Keras)' [1~3탄]을 통해서 전이 학습(transfer learning)에 대한 실습을 진행해보았는데요, 이론적인 내용이 부족했던 것 같아 공부한 내용을 함께 공유해보려고 합니다.
이 글을 먼저 천천히 읽어보시고 실습을 진행해보시면 좋을 것 같네요.
위키 백과에서는 '한 분야의 문제를 해결하기 위해서 얻은 지식과 정보를 다른 문제를 푸는데 사용하는 방식'으로 정의하고 있는데요
이를 딥러닝의 분야에서는 '이미지 분류' 문제를 해결하는데 사용했던 네트워크(DNN;Deep Neural Network)를 다른 데이터셋 혹은 다른 문제(task)에 적용시켜 푸는 것을 의미합니다. 특히나 기계의 시각적 이해를 목표로 하는 컴퓨터 비전의 영역에서 전이 학습으로 수행된 모델들이 높은 성능을 보이고 있어 가장 많이 사용되는 방법 중에 하나입니다. 전이학습을 수행하지 않은 모델들보다 비교적 빠르고 정확한 정확도를 달성할 수 있는 것이죠. 어떻게 이런 것들이 가능할까요?
바로 네트워크가 다양한 이미지의 보편적인 특징 혹은 피처(Feature)들을 학습했기 때문입니다. 일반적으로 네트워크가 깊어질수록 서로 다른 종류의 피처들을 학습한다고 알려져 있는데요 낮은 층에서 학습되는 피처를 low-level features, 깊은 층에서 학습되는 피처들은 high level features라고 부릅니다. low-level feature의 예로는 이미지의 색이나 경계(edge) 등을 말할 수 있고 high level features는 이보다 더 심화된 객체의 패턴이나 형태를 의미합니다. 그림 1을 보시면 각각의 단계에서 이미지의 특징들을 추출하는 필터를 시각화한 그림입니다. 단계별로 서로 다른 형태를 띄고 있음을 알 수 있습니다. low-level feature의 필터의 경우 색의 변화나 경계의 방향 등을 추출한다고 유추할 수 있고 더 올라가서 high-level feature는 동그라미가 반복되는 패턴이나 새의 부리 등의 이미지를 분류하는데 있어서 주요한 특징들을 학습한다고 말할 수 있겠습니다.

그림1. multi-level-features [출처 : Kaggle]
네트워크가 이러한 특징을 학습하기 위해서는 대량의 데이터셋이 필요한데 가장 대표적으로 ImageNet을 들 수 있습니다. ImageNet은 2010년~2017년까지 매해 열린 대회 ImageNet Large-Scale Visual Recognition (ILSVRC)을 위한 데이터셋으로 자동차나 고양이를 포함한 1000개의 클래스, 총 1400만개의 이미지로 구성되어 있습니다. 해당 데이터셋을 가지고 이미지 분류를 수행한 모델들은 매년 뛰어난 성능을 보여주고 있는데 2015년 이후에는 사람보다 뛰어난 정확도를 가진 모델이 등장하였습니다. 참고로 Russakovsky et al 에 따르면 사람의 이미지 분류 오류는 5.1%에 달합니다.

그림 2. ILSVRC [출처 : ResearchGate]
2012년 AlexNet 이후에 VGG, GoogleNet, ResNet 등 주요 CNN 구조들은 전이 학습을 수행하는데 네트워크의 기저(base 또는 backbone)으로 사용되고 있습니다. 논문을 살펴보면 ResNet을 기반으로 한 여러 모델을 찾아보실 수 있으실 겁니다. ImageNet으로 학습시킨 CNN 구조는 정말 많이 사용되기 때문에 pytorch나 tensorflow 같은 딥러닝 프레임워크에서 API 저장되어 있어 간편하게 불러와서 사용하실 수 있습니다. 이렇게 구현할 수 있는 모델의 목록은 공식 문서(tensorflow, keras, pytorch) 등을 통해 확인하실 수 있습니다. 주요 CNN 구조인 GoogleNet과 ResNet에 대해서는 장어님이 토크를 올려주셨네요. 중요한 구조이니만큼 꼭 게시글을 확인해보시면 좋을 것 같습니다.
전이학습은 실제로 어떻게 이루어질까요?
전이학습을 위해서는 ImageNet과 같은 대량의 데이터셋으로 이미 학습이 되어있는 모델을 사용합니다. 이를 '사전에 학습된 모델' 혹은 'pretrained model'이라고 부릅니다. 데이콘 대회에 참여하시면서 규정사항에 pretrained model을 사용할 수 있다/없다 등으로 접해본 용어일 수도 있겠네요.
몇가지 경우에 대해서 pretrained 모델 외에 학습시키는 레이어의 양이 달라질 수 있습니다. 그림 3을 참고해주세요.
만약 ImageNet과 비슷하지만 소량의 데이터셋을 가지고 있다면 ImageNet으로 학습시킨 CNN을 구조를 그대로 두고 뒷단에 분류를 위해 새로운 완전연결레이어(FC;Fully Connected Layer)를 붙여서 학습시키면 됩니다. 만약 ImageNet과 비슷하지만 더 많은 데이터셋을 가지고 있다면 뒷단에 여러 FC레이어를 묶어서 학습시켜도 좋습니다.
만약 내가 가진 데이터셋이 ImageNet과 다른 경우에는 어떨까요? 데이터가 많은 경우에 뒷단의 여러 FC 레이어를 묶어서 학습시키는 것이 충분할 것입니다. 하지만 데이터가 적은 경우엔 pre-training이 효과적이지 않을 수 있습니다. 데이터 증식으로 데이터의 양을 늘려서 전체 네트워크를 학습시키는 등 다른 방법을 생각해야합니다.
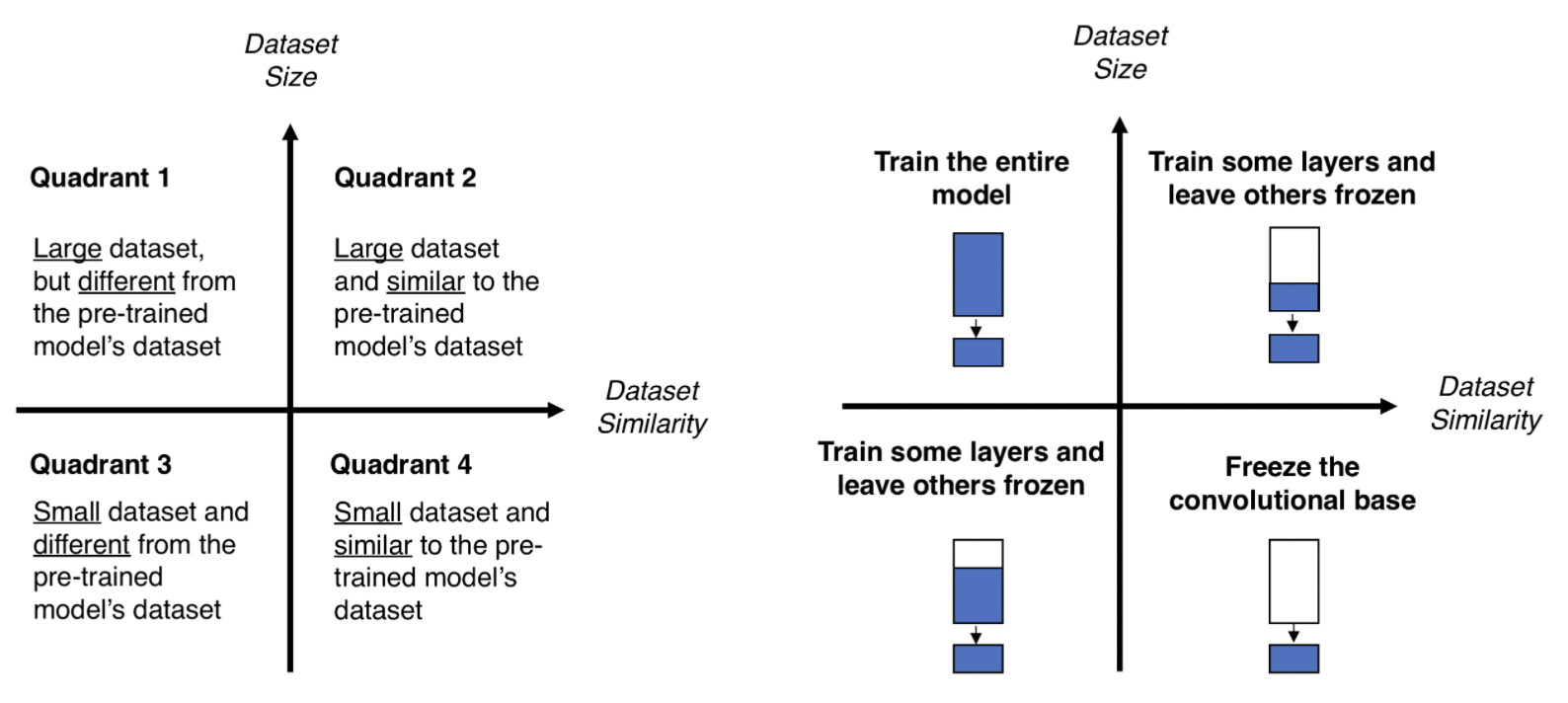 그림 3. pre-training [출처:Kaggle]
그림 3. pre-training [출처:Kaggle]
전이학습, 이론적으로는 알겠으나 실제로 효과가 있는 것이 맞나? 나는 그냥 기본 모델에서 학습시키면 되는데?라고 생각하실 수도 있습니다. 이에 대한 답으로 2018년 FAIR(Facebook AI Research) 논문에서 실험을 통해 '전이학습이 학습 속도 면에서 효과가 있다'라는 것을 밝혀냅니다. 동일한 조건에서 바닥부터 훈련시키는 것(train from the scratch)이 사전 학습된 모델을 사용하는 것보다 2~3배의 시간이 더 걸린다는 것을 보여주고 있습니다. 그림 4에서 랜덤으로 모델을 초기화를 시키는 것보다 사전 학습된 모델의 초기값을 사용하였을 때 더 빠르게 높은 정확도에 도달한다는 것을 보여주고 있습니다. 더 궁금하신 분들은 논문을 읽어보셔도 좋겠네요.
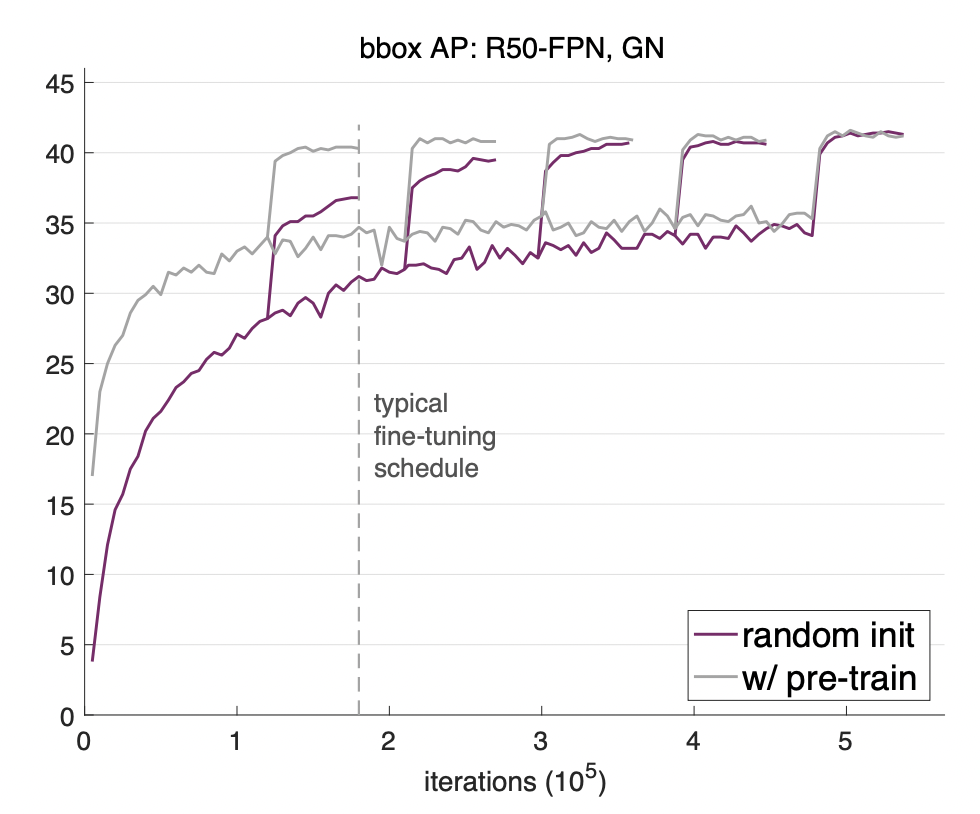
그림 4. Rethinking ImageNet Pre-training [출처 : arxiv]
오늘은 전이학습과 사전 학습된 모델에 대해서 정리해보았습니다.
더 궁금한 사항이나 피드백 있으시면 언제나 편하게 댓글 달아주세요. 🤗
긴 글 읽어주셔서 감사합니다.
긴 글 읽어주셔서 감사합니다. 도움이 되었다니 기쁘네요😀
정리가 명확해서 읽기도 편했고 이해도 잘 되었습니다. 감사합니다 :)
데이터셋이 ImageNet과 같고 다르다는 말이 무슨 말인가요? 제가 가진 이미지 데이터를 ImageNet이 학습한 적 있는지를 말하는 건가요 아님 다른걸 말하는건가요??
내가 풀고자 하는 문제의 이미지 데이터셋이 ImageNet 데이터와 특징이 다를 경우를 말합니다.
예를 들어서, 선생님께서 풀고 싶은 문제는 CT 의료 이미지 데이터를 분류하는 문제라고 한다면 이 이미지는 ImageNet 이미지와는 다른 특징을 가진 데이터이기 때문에 전이학습 시 이를 고려하여 학습시킬 레이어의 양을 정해주어야 합니다.
아하 감사합니다! 이해했습니다. 써주신 글도 도움이 많이 됐습니다!!
전이 학습에 대해 확실하게 이해하고 갑니다!
삭제된 댓글입니다
삭제된 댓글입니다
데이콘(주) | 대표 김국진 | 699-81-01021
통신판매업 신고번호: 제 2021-서울영등포-1704호
직업정보제공사업 신고번호: J1204020250004
서울특별시 영등포구 은행로 3 익스콘벤처타워 901호
이메일 dacon@dacon.io |
전화번호: 070-4102-0545
Copyright ⓒ DACON Inc. All rights reserved
 목록으로
목록으로
전이 학습이 무엇인지 정확하게 알지 못하였는데요, 잘 정리된 글과 이해에 도움이 되는 그림을 통해 작성하신 동화책님의 게시물을 읽고 개념을 확실하게 잡아갈 수 있었습니다!
많은 도움 얻고 갑니다! 좋은 게시물 감사합니다 :)