

데이스쿨 할인 리턴즈
2022 Samsung AI Challenge (3D Metrology)
안녕하세요 다들 어떤식으로 접근하고 계신가 궁금해서, 저희팀의 전략을 공개합니다!
저희팀은 현재 3명으로 구성되어있으며, 현재 Public LB 기준 6.5 정도의 Score를 기록하고 있습니다.
처음에 시작했을 때 그리고 현재의 점수까지 많은 변화가 있어 차근히 공개해보겠습니다.
먼저 Dataset을 이해하는데 꽤나 오랜시간이 걸렸습니다. (토크 게시판을 보면 다들 그런거 같기도...? ㅋㅋ)
최종적 이해된 부분은 (Simulation) Depth map -> SEM Image로의 과정은 GAN과 같은 model 같은 걸로 "생성"한 것이고,
train은 실제 Depth map은 없지만, test와 동일한 Image distribution을 가진 Data이다. 라고 생각했습니다.
그래서 데이터셋을 이해한 뒤 처음으로 접근한 방법은 GAN입니다.
현재 (Simulation)Depth map -> SEM으로의 Generation을 GAN으로 생성했겠거니 생각했고(사실 지식이 짧아, Generation 류는 GAN밖에 잘모릅니다.. ㅎㅎ)
해당 과정의 Generation의 역함수 형태의 GAN을 학습하고 재현할 수 있으면 굉장히 좋은 접근 및 결과를 얻을 수 있을 것이라 생각했습니다.
즉 저희는 SEM -> Depth map으로의 모델을 (simulation) Depth -> SEM 의 역함수 형태로 구성했습니다. (물론 여기까지 접근할 때에도 Depth map의 픽셀형태와 실제 train/test SEM을 보고 만들어야 하는 Depth map의 pixel형태(단위)가 다르면 어쩌나 싶었는데, 다행히도 아니라는 것을 토크 게시판을 통해 알게되었습니다)
해당 컨셉과 가장 유사한 Architecture로 CycleGAN을 선택했습니다.
간단히 소개하자면, 2개의 Generator와 2개의 Discriminator가 있어 서로다른 2개의 도메인의 image를 보고 학습해 cycle consistency를 유지하도록 하는 형태입니다.
논문의 이름은. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 입니다.
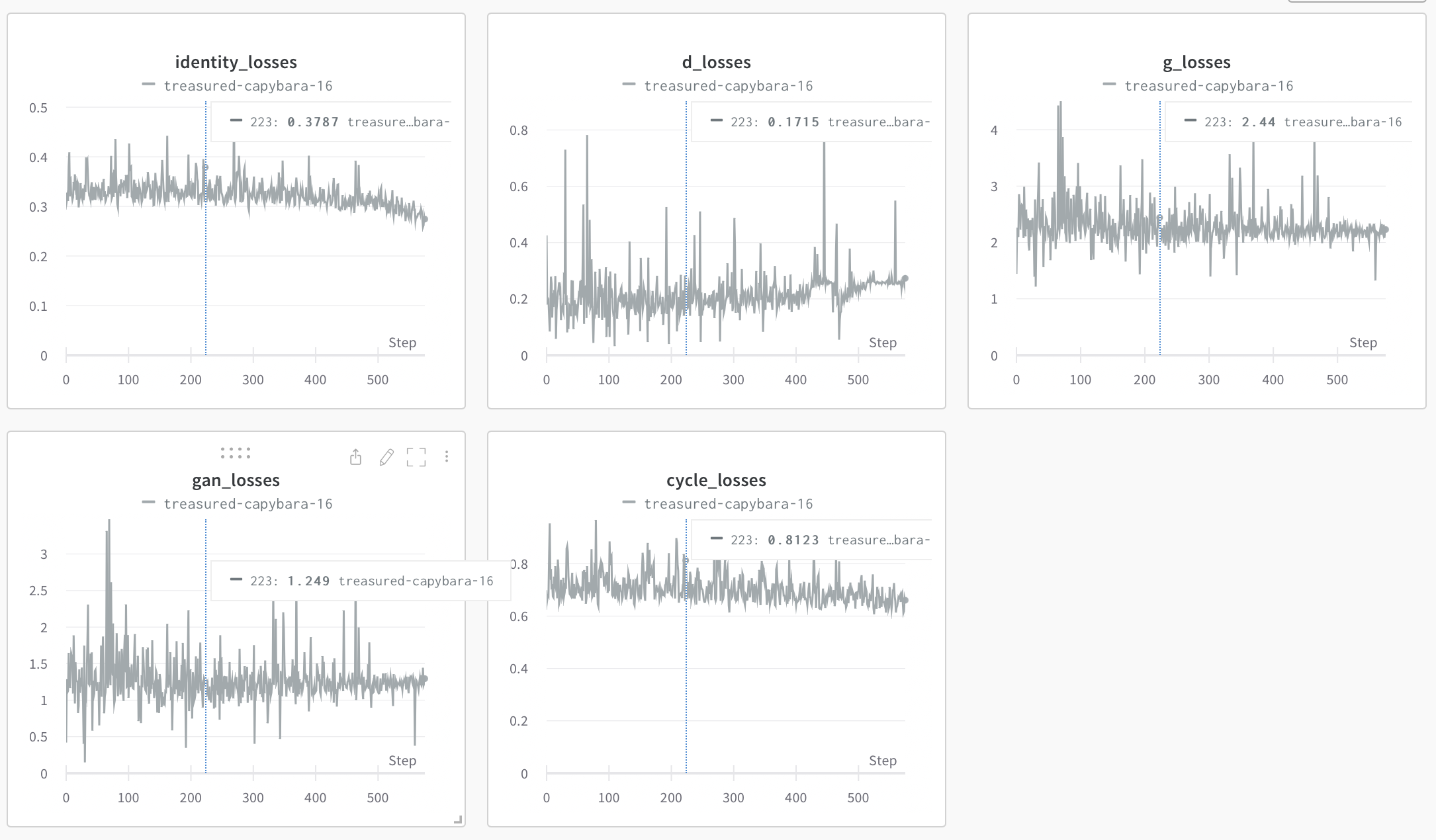
논문을 보고, 샘플 코드 보며 어렵사리 구현에 성공했고(그렇게 믿습니다 ㅋㅋ) 결과는 다음과 같습니다.
첫번째 사진이 GT이고 두번째 사진이 Generation된 sample입니다.
이렇게 제출했을 때 아마 14정 정도 나왔습니다. 다만 학습에 200epoch, 2일 조금 넘게 걸렸던 것으로 기억하네요. (colab환경으로 진행했습니다... 처절한 런타임과의 싸움...)


학습에는 Cycle Consistency Loss = L1, identity = L1, adversarial loss에는 MSE를 사용했습니다.(생각해보니, gray scale인데 identity loss를 뺄 걸 그랬나 싶기도 하네요..)
쨌든 14점과 top score와의 간극은 굉장히 컸고, 이를 매꿀 획기적인 방법이 필요했습니다.
이제 다음으로 생각해봤던건 Depth Estimation입니다.
? 이게 뭐임 할 수도 있는데, 저도 그냥 서칭하다가 이런것들도 가능하구나... 싶었고, 처음 봤습니다 ㅋㅋ
아무튼 소개를 안하려다가, 이런 Task도 있고, 이런 삽질도 했구나 정도로 넘어가시면 좋습니다.
말 그대로 깊이를 측정하는 Task이고, 뭣도 모르니, "SEM -> Depth map이니까 각 pixel별로 깊이를 측정할 수 있다면?! 오쮓, 이거 히트다"
라는 생각으로 바로 SOTA로 논문 읽고 들이박아보았습니다.
결론은 2D image로 Depth estimation을 하고자 함은, 다양한 meta 정보 혹은 sensor의 정보가 필요했습니다.
그 이유는 바로 2D -> depth(3D)로의 확장은 무한히 많은 함수로 mapping이 되기 때문입니다. 고로 이를 한정하는 다른 정보들이 필요한데, 저희 Task의 경우 그러한 정보가 없으니, 불가능합니다.(그래서 그냥 한다고 하면 2D image상에서 서로 다른 Feature(사물)들 간의 위치관계 정도...?를 정의할 수 있다(?), 아무튼 실패입니다.)
짧은 시간 많은 영어를 보고 어지러움을 느끼고, 팀원 중 한분에 U-Net을 통해 접근을 하고 계시다는 얘기를 들었습니다.
왜 하필 U_Net인지에 대해서는 사실 명확한 institution은 없지만, Segmentation처럼 Hole의 외곽이 중요하니 한번 해봤다. 정도로 이해를 하면 좋을 것 같습니다.
아무튼 기존의 U_Net에 output을 Segmentation(pixel classification)이 아닌 pixel wise regression이 적용되어야 하니, convolution layer를 통해 최종 output이 생성되도록 output을 모델링했습니다.
결과는 약 Public LB 기준 6.7 정도 나왔습니다.
많이 높아졌지만, 생각보다 그다지 높은 수치라고는 생각되지 않습니다.
이제 base model은 U-Net으로 하고 이제 후처리를 신경써보기로 했습니다.
토크 게시판에서도 background를 예측해 140, 150, 160, 170으로 한정해서 성능이 많이 올라갔다라는 말도 있었고, 저희는 EDA를 통해 Depth map이 그러한 특징을 보유한 것을 알아 이를 한정해보기로 했습니다.
하지만 단순히 U-Net으로 만들어진 background를 다양한 값이 있어, 단순히 140, 150, 160, 170으로 바꾸기에는 어려움이 있었습니다.
그래서 먼저 background를 예측할 수 있는 Classification 모델을 하나 만들어 해당 값을 토대로 한번 진행해보았습니다.
validation 기준 0.88 정도 나오는 resnet18이였고, 해당 값을 토대로 background를 대강 고쳐보니 6.5정도로 소폭의 성능향상이 있었습니다.
이제 마지막으로 "어디까지가 Hole이고 background인지 명확히 분리할 필요가 있었습니다."
다시 U_net을 가져와 Segmentation Task를 수행하고자 했습니다. 그럼 이걸 어떻게 하냐?
(simulation) SEM -> Depth map(0, 1 segmentation)을 수행하도록 했습니다. (simluation)Depth map Image는 만약 140이 배경이라면, Hole에는 140의 값이 없었고, 이를 이용해 Hole과 background를 labeling할 수 있었습니다.
이렇게 labeling된 image를 다시 segmentation해서, 해당 pixel에만 background pixel로 적용되도록 했습니다. 결과적으로 LB 기준 6.6의 score를 기록했습니다.
저희 내부에서는 Segmentation의 성능이 너무 좋아 아마 classification 모델의 성능이 현재 안 좋을 것으로 판단합디다. 고로 해당 성능을 높이기 위해 soft voting 혹은 hard voting을 이용한 앙상블을 적용 중에 있으며, 해당 내용도 완료된다면 공유해보겠습니다....
여러분들도 어떤 모델로 어떻게 적용하셨는지 댓글이나 토크 게시판을 통해 많이 공유해주세요...
혹시 Dacon에서 제공해준 Baseline은 사용을 안하신건가요? 안하셨다면 이유가 궁금합니다
안녕하세요. 사실 Baseline은 Baseline이니까 라는 생각이 가장 큽니다.
제 짧은 식견으로 Baseline은 아마 Linear layer를 이용한 Stacked Auto-encoder의 형태라고 생각하는데, Baseline을 기준으로 더 layer를 쌓거나, convolution의 형태로 Auto-encoder를 만들어도 좋은결과를 얻을 것 같습니다!
좋은 의견 감사합니다
좋은 의견 공유 감사합니다!
감사합니다~!
데이콘(주) | 대표 김국진 | 699-81-01021
통신판매업 신고번호: 제 2021-서울영등포-1704호
직업정보제공사업 신고번호: J1204020250004
서울특별시 영등포구 은행로 3 익스콘벤처타워 901호
이메일 dacon@dacon.io |
전화번호: 070-4102-0545
Copyright ⓒ DACON Co.,Ltd All rights reserved
 목록으로
목록으로
Public LB score가 6.7이네요 ㅋㅋ 본문 내용을 6.7 -> 6.9로 이해하시고, 나머지 값들도 조금씩 높여서 이해하시면 좋을 거 같습니다 ㅋㅋ