

데이스쿨 할인 리턴즈
사이버 공격 유형 예측 해커톤: 트래픽 속 위협을 식별하라!
EDA 및 주요 인사이트
EDA 및 주요 인사이트 작성하였습니다.
좋은 의견 있으면 가감 없이 부탁 드립니다.
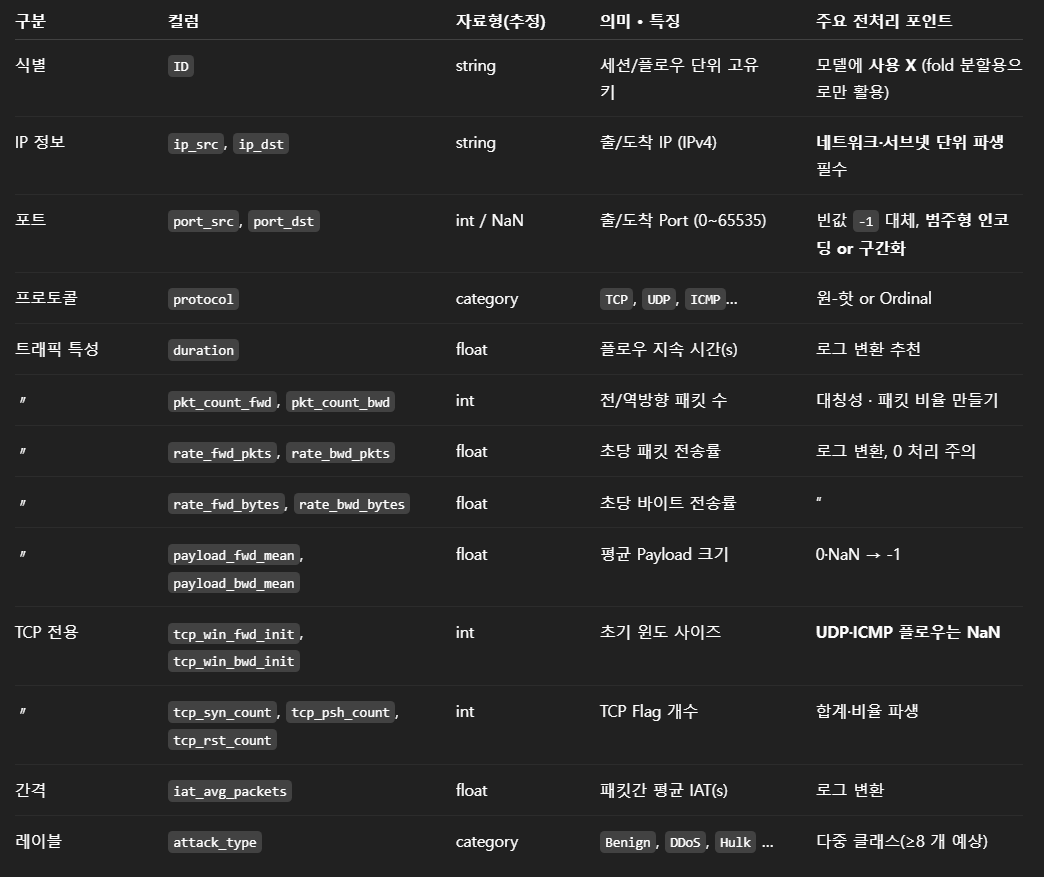
2.기본 EDA
# ==============================================================
# Cell 1 ▸ 라이브러리 로드 & 데이터 읽기
# ==============================================================
import pandas as pd, numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
pd.set_option("display.max_columns", 200)
plt.style.use("ggplot")
PATH = "/path/train.csv" # 데이터 경로
df = pd.read_csv(PATH)
print("shape :", df.shape)
df.head()
# ==============================================================
# Cell 2 ▸ target(attack_type) 클래스 분포
# ==============================================================
cls_cnt = df["attack_type"].value_counts().sort_values(ascending=False)
print(cls_cnt)
plt.figure(figsize=(10,4))
sns.barplot(x=cls_cnt.index, y=cls_cnt.values, palette="viridis")
plt.xticks(rotation=45, ha="right")
plt.title("Class Distribution (attack_type)")
plt.ylabel("# samples")
plt.tight_layout()
plt.show()
attack_type Benign 8791 Hulk 1719 Port_Scanning 793 DDoS 471 FTP_Brute_Force 47 GoldenEye 41 Slow_HTTP 34 SSH_Brute_Force 30 Botnet 27 Slowloris 26 Web_Brute_Force 14 Web_XSS 6
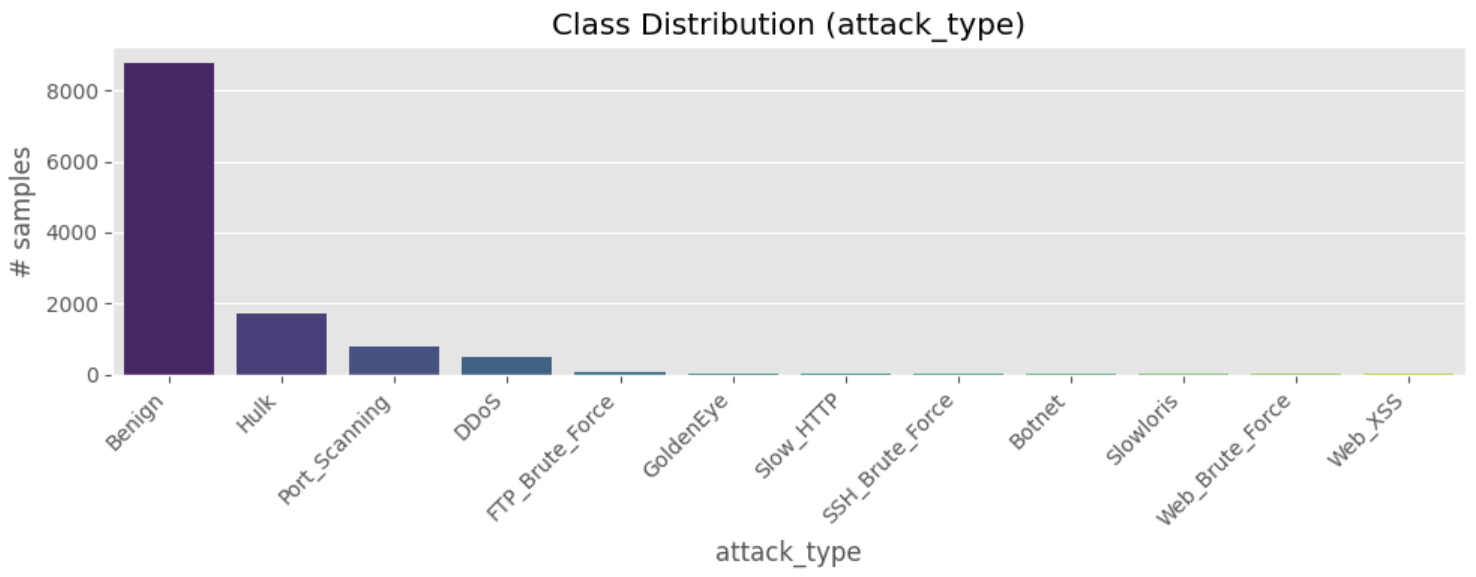
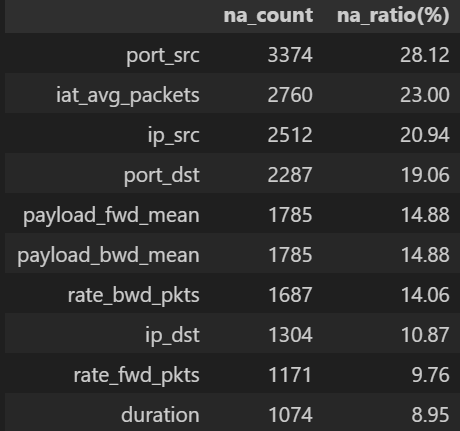
# ==============================================================
# Cell 3 ▸ 전체 결측치 분포
# ==============================================================
na_sum = df.isna().sum()
na_table = na_sum[na_sum>0].sort_values(ascending=False).to_frame("na_count")
na_table["na_ratio(%)"] = (na_table["na_count"] / len(df) * 100).round(2)
display(na_table.head(20)) # 상위 20개만
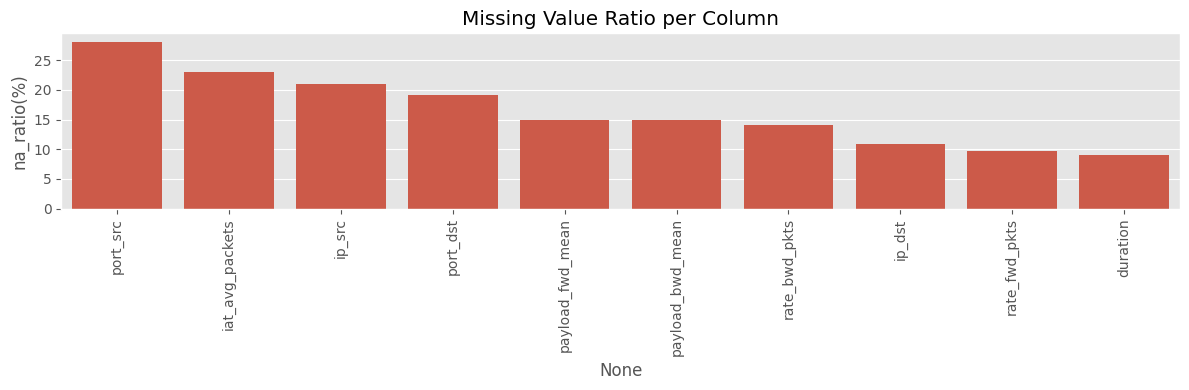
plt.figure(figsize=(12,4))
sns.barplot(x=na_table.index, y="na_ratio(%)", data=na_table)
plt.xticks(rotation=90)
plt.title("Missing Value Ratio per Column")
plt.tight_layout()
plt.show()
# ==============================================================
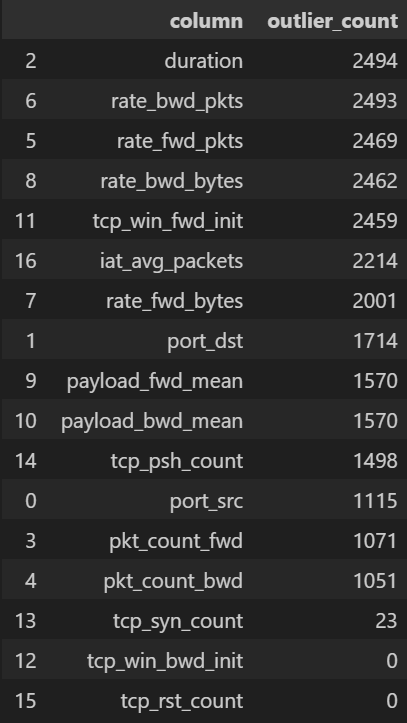
# Cell 4 ▸ 숫자형 컬럼별 이상치 탐지 (IQR 기반)
# ==============================================================
num_cols = df.select_dtypes(include=[np.number]).columns.tolist()
outlier_info = []
for col in num_cols:
q1, q3 = df[col].quantile([0.25, 0.75])
iqr = q3 - q1
lower = q1 - 1.5 * iqr
upper = q3 + 1.5 * iqr
out_cnt = df[(df[col] < lower) | (df[col] > upper)].shape[0]
outlier_info.append((col, out_cnt))
out_df = pd.DataFrame(outlier_info, columns=["column", "outlier_count"])\
.sort_values("outlier_count", ascending=False)
display(out_df.head(20))
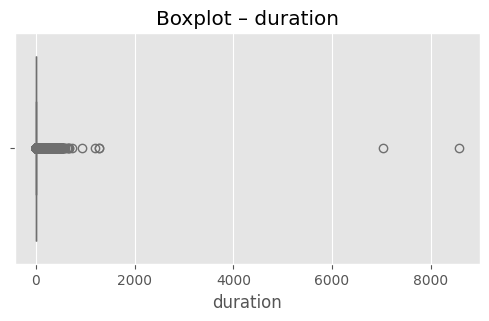
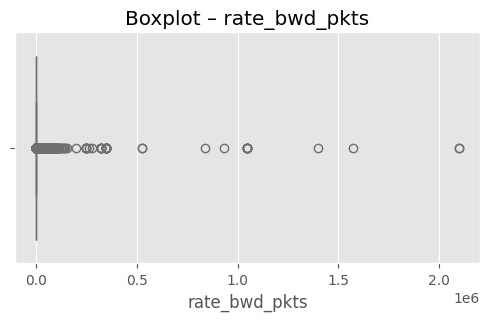
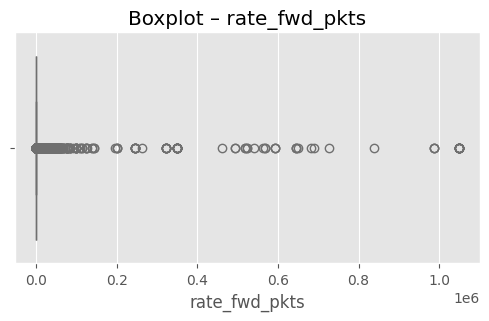
# (옵션) 가장 이상치가 많은 상위 3개 컬럼 시각화
top3 = out_df.head(3)["column"].tolist()
for col in top3:
plt.figure(figsize=(6,3))
sns.boxplot(x=df[col], color="skyblue")
plt.title(f"Boxplot – {col}")
plt.show()
# ==============================================================
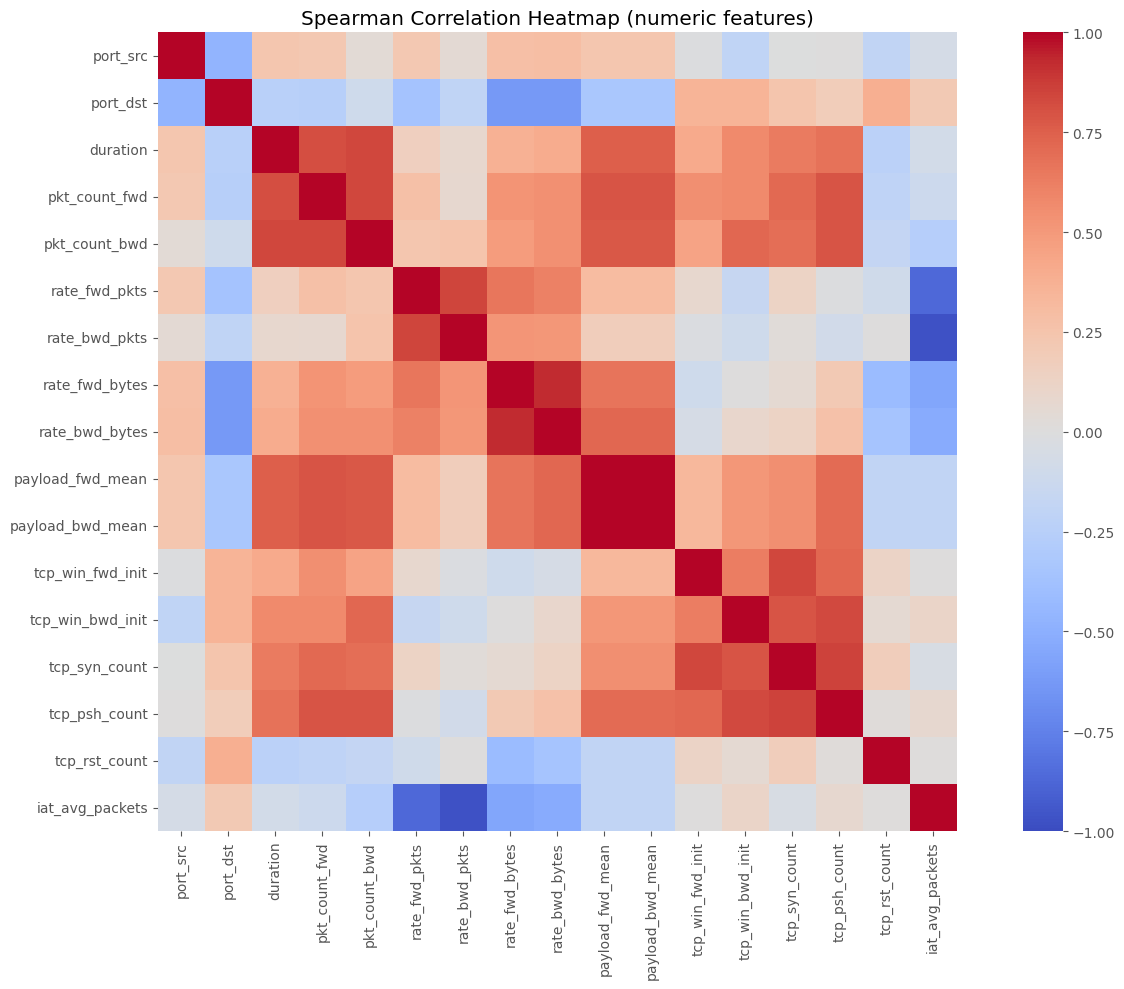
# Cell 5 ▸ 컬럼별 기본 통계 & 상관관계 히트맵 (선택)
# ==============================================================
print(df.describe(include="all").T.head(20)) # 필요 시 전체 저장
plt.figure(figsize=(14,10))
corr = df[num_cols].corr(method="spearman")
sns.heatmap(corr, cmap="coolwarm", center=0, vmin=-1, vmax=1, square=True)
plt.title("Spearman Correlation Heatmap (numeric features)")
plt.tight_layout()
plt.show()
count unique top freq mean \ ID 11999 11999 TRAIN_00000 1 NaN ip_src 9487 517 172.16.0.182 2266 NaN port_src 8625.0 NaN NaN NaN 42746.90342 ip_dst 10695 1901 192.168.10.18 2681 NaN port_dst 9712.0 NaN NaN NaN 6445.632619 protocol 11999 2 TCP 8005 NaN duration 10925.0 NaN NaN NaN 16.712027 pkt_count_fwd 11999.0 NaN NaN NaN 16.019168 pkt_count_bwd 11999.0 NaN NaN NaN 20.222685 rate_fwd_pkts 10828.0 NaN NaN NaN 6645.382033 rate_bwd_pkts 10312.0 NaN NaN NaN 6627.535999 rate_fwd_bytes 11999.0 NaN NaN NaN 320568.776422 rate_bwd_bytes 11999.0 NaN NaN NaN 188760.733033 payload_fwd_mean 10214.0 NaN NaN NaN 183.602231 payload_bwd_mean 10214.0 NaN NaN NaN 183.602231 tcp_win_fwd_init 11999.0 NaN NaN NaN 8464.43587 tcp_win_bwd_init 11999.0 NaN NaN NaN 8691.062839 tcp_syn_count 11999.0 NaN NaN NaN 0.713976 tcp_psh_count 11999.0 NaN NaN NaN 2.409451 tcp_rst_count 11999.0 NaN NaN NaN 0.324027 std min 25% 50% 75% \ ID NaN NaN NaN NaN NaN ip_src NaN NaN NaN NaN NaN port_src 20898.422967 11.0 35892.0 51267.0 58154.0 ip_dst NaN NaN NaN NaN NaN port_dst 16426.098766 0.0 58.0 83.0 447.0 protocol NaN NaN NaN NaN NaN duration 120.178667 0.0 0.000037 0.023343 0.363972 pkt_count_fwd 1125.156847 0.0 1.0 2.0 6.0 pkt_count_bwd 1559.513622 0.0 1.0 2.0 5.0 rate_fwd_pkts 49400.352987 0.0 0.0 7.683389 84.858991 rate_bwd_pkts 52039.407437 0.0 0.014556 14.772424 501.153578 rate_fwd_bytes 6399729.624371 0.0 0.0 24.792465 2209.445479 rate_bwd_bytes 1183179.128635 0.0 0.0 414.200061 8446.479825 payload_fwd_mean 312.584458 0.0 0.0 61.5 141.0 payload_bwd_mean 312.584458 0.0 0.0 61.5 141.0 tcp_win_fwd_init 15043.771463 0.0 0.0 0.0 8192.0 tcp_win_bwd_init 14180.141107 0.0 0.0 0.0 26847.0 tcp_syn_count 1.010957 0.0 0.0 0.0 2.0 tcp_psh_count 13.620653 0.0 0.0 0.0 2.0 tcp_rst_count 0.46803 0.0 0.0 0.0 1.0 max ID NaN ip_src NaN port_src 65535.0 ip_dst NaN port_dst 65384.0 protocol NaN duration 8567.023224 pkt_count_fwd 123229.0 pkt_count_bwd 170796.0 rate_fwd_pkts 1048576.0 rate_bwd_pkts 2097152.0 rate_fwd_bytes 509484574.117647 rate_bwd_bytes 53292333.176471 payload_fwd_mean 2433.333333 payload_bwd_mean 2433.333333 tcp_win_fwd_init 65535.0 tcp_win_bwd_init 65535.0 tcp_syn_count 9.0 tcp_psh_count 1046.0 tcp_rst_count 1.0
3.추가 EDA 분석
# ============================================================== # Cell 0 ▸ 공통 설정 # ============================================================== import pandas as pd, numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn.manifold import TSNE from sklearn.preprocessing import StandardScaler from sklearn.model_selection import StratifiedKFold try: import umap # optional except ImportError: umap = None PATH = "/path/train.csv" df = pd.read_csv(PATH) print(df.shape)
1) IP 주소 → 서브넷 파생 필요성 확인
# ==============================================================
# Cell 1-A ▸ IP 옥텟 분해 & 빈도표
# ==============================================================
for side in ["src", "dst"]:
octets = df[f"ip_{side}"].str.split('.', expand=True)
octets.columns = [f"ip_{side}_{i}" for i in range(4)]
df = pd.concat([df, octets.astype(float)], axis=1)
for col in ["ip_src_0", "ip_dst_0", "ip_src_1", "ip_dst_1"]:
print("\nTop 10 –", col)
print(df[col].value_counts(dropna=False).head(10))
Top 10 – ip_src_0 ip_src_0 192.0 6457 NaN 2512 172.0 2310 23.0 54 52.0 54 104.0 45 162.0 44 178.0 42 54.0 35 199.0 33 Name: count, dtype: int64 Top 10 – ip_dst_0 ip_dst_0 192.0 7177 NaN 1304 172.0 725 23.0 345 52.0 314 104.0 222 54.0 206 151.0 127 162.0 126 72.0 100 Name: count, dtype: int64 Top 10 – ip_src_1 ip_src_1 168.0 6444 NaN 2512 16.0 2279 217.0 50 255.0 37 208.0 35 244.0 31 67.0 25 241.0 24 63.0 17 Name: count, dtype: int64 Top 10 – ip_dst_1 ip_dst_1 168.0 7108 NaN 1304 217.0 431 16.0 356 101.0 126 208.0 125 84.0 120 194.0 88 21.0 74 192.0 68 Name: count, dtype: int64
# ==============================================================
# Cell 1-B ▸ /24 동일 서브넷 플래그 & 크로스탭
# ==============================================================
df["same_subnet_24"] = (
(df["ip_src_0"] == df["ip_dst_0"]) &
(df["ip_src_1"] == df["ip_dst_1"]) &
(df["ip_src_2"] == df["ip_dst_2"])
)
subnet_ct = pd.crosstab(df["same_subnet_24"], df["attack_type"], normalize="columns") * 100
display(subnet_ct.style.format("{:.1f}%"))

# ==============================================================
# Cell 1-C ▸ t-SNE / UMAP 시각화 (선택)
# ==============================================================
cols = [f"ip_src_{i}" for i in range(4)] + [f"ip_dst_{i}" for i in range(4)]
ip_mat = df[cols].fillna(-1)
emb = TSNE(perplexity=50, random_state=0).fit_transform(ip_mat)
# UMAP을 쓰려면: emb = umap.UMAP(min_dist=0.3).fit_transform(ip_mat)
plt.figure(figsize=(6,5))
sns.scatterplot(x=emb[:,0], y=emb[:,1], hue=df["attack_type"],
palette="tab10", s=10, linewidth=0, alpha=0.6)
plt.title("t-SNE of IP-octets")
plt.legend(bbox_to_anchor=(1,1))
plt.tight_layout()
plt.show()
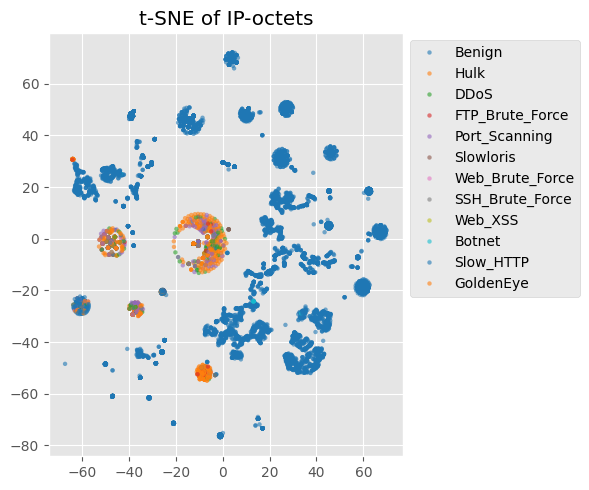
주요 인사이트
(1) IP 옥텟 분포
(2) same_subnet_24” 결과
(3) t-SNE 시각화 해석
2) 포트 빈값과 구간화 필요성
# ==============================================================
# Cell 2-A ▸ 빈값 비율
# ==============================================================
for col in ["port_src", "port_dst"]:
na_pct = df[col].isna().mean()*100
blank_pct = (df[col]=="").mean()*100 if df[col].dtype=="object" else 0
print(f"{col}: NaN={na_pct:.2f}%, blank={blank_pct:.2f}%")
port_src: NaN=28.12%, blank=0.00% port_dst: NaN=19.06%, blank=0.00%
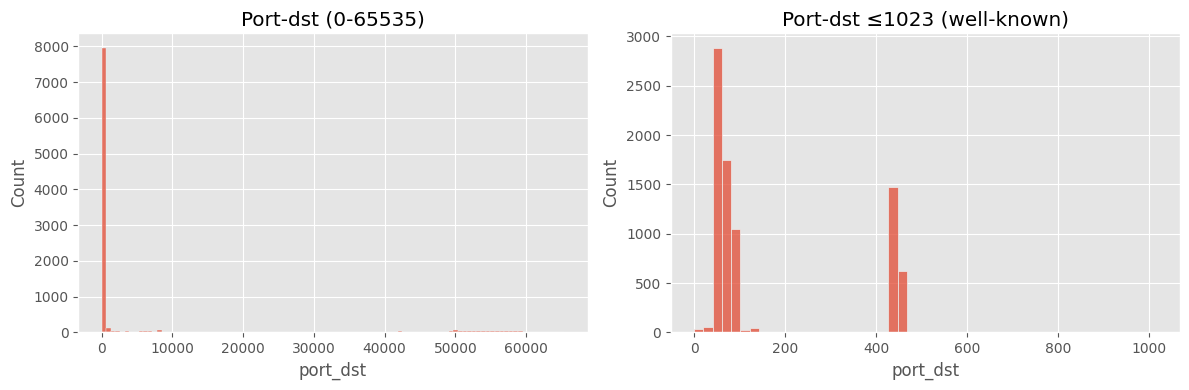
# ==============================================================
# Cell 2-B ▸ 포트 히스토그램 (전체 & well-known 확대)
# ==============================================================
fig, ax = plt.subplots(1,2, figsize=(12,4))
sns.histplot(df["port_dst"].dropna(), bins=100, ax=ax[0])
ax[0].set_title("Port-dst (0-65535)")
sns.histplot(df[df["port_dst"]<=1023]["port_dst"].dropna(), bins=50, ax=ax[1])
ax[1].set_title("Port-dst ≤1023 (well-known)")
plt.tight_layout(); plt.show()
# ==============================================================
# Cell 2-C ▸ 포트 버킷 vs 클래스
# ==============================================================
bins = [-10,0,1024,49152,70000]
labels = ["missing","well","registered","dynamic"]
for col in ["port_src","port_dst"]:
df[f"{col}_bucket"] = pd.cut(df[col].fillna(-1), bins=bins, labels=labels)
bucket_ct = pd.crosstab(df["port_dst_bucket"], df["attack_type"], normalize="columns")*100
display(bucket_ct.style.format("{:.1f}%"))

주요 인사이트
port_src·port_dst 에 결측값(NaN)이 일부 존재3) duration 로그 변환 타당성
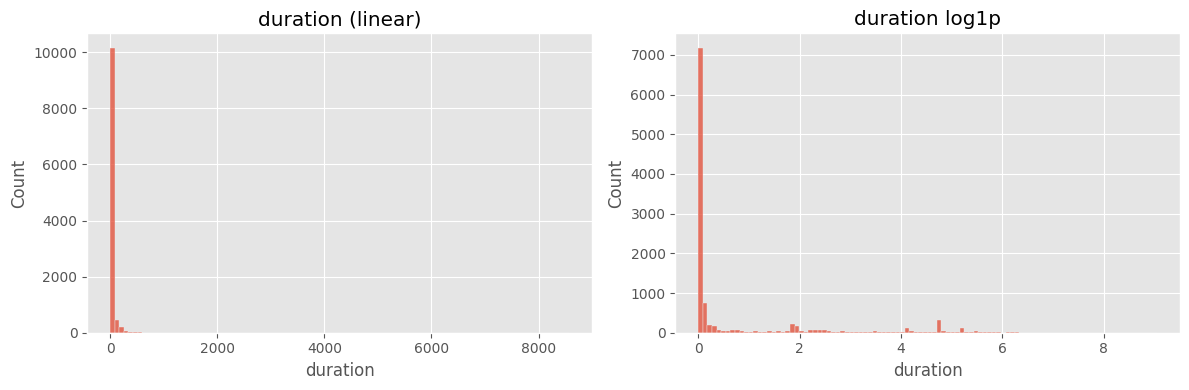
# ==============================================================
# Cell 3-A ▸ 히스토그램 선형 vs 로그
# ==============================================================
fig, ax = plt.subplots(1,2, figsize=(12,4))
sns.histplot(df["duration"].dropna(), bins=100, ax=ax[0])
ax[0].set_title("duration (linear)")
sns.histplot(np.log1p(df["duration"].dropna()), bins=100, ax=ax[1])
ax[1].set_title("duration log1p")
plt.tight_layout(); plt.show()
# ==============================================================
# Cell 3-B ▸ 박스플롯
# ==============================================================
plt.figure(figsize=(10,4))
sns.boxplot(x="attack_type", y="duration", data=df, showfliers=False)
plt.yscale("log")
plt.xticks(rotation=45, ha="right")
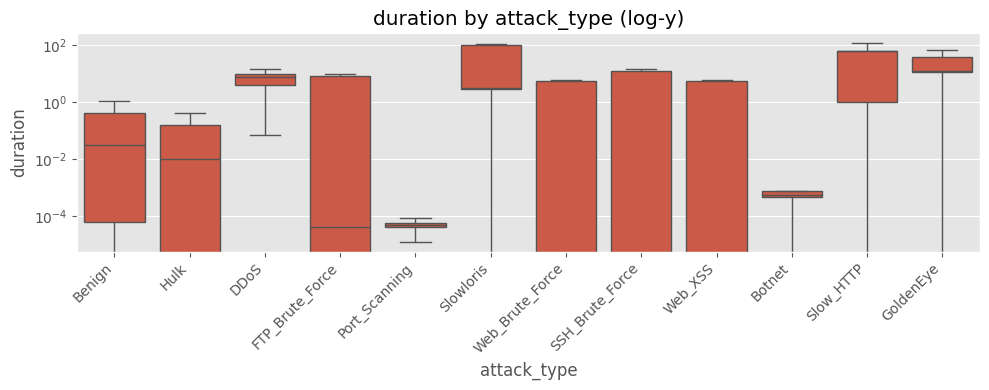
plt.title("duration by attack_type (log-y)")
plt.tight_layout(); plt.show()
# ==============================================================
# Cell 3-C ▸ QQ-plot
# ==============================================================
import scipy.stats as stats
stats.probplot(np.log1p(df["duration"].dropna()), dist="norm", plot=plt)
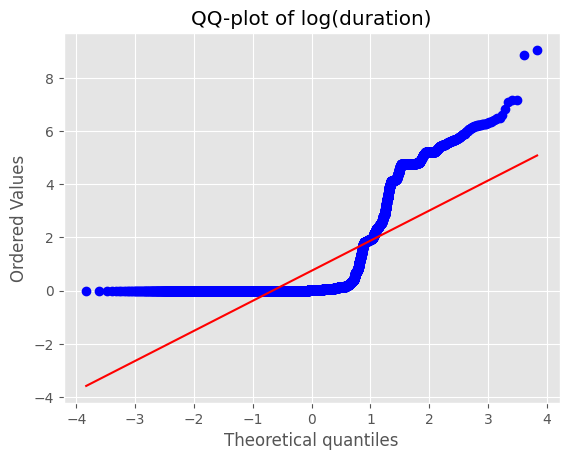
plt.title("QQ-plot of log(duration)")
plt.show()
주요 인사이트
duration) 분포가 0~10⁵ 초까지 극단적으로 퍼져 있고, 중간값과 최대값 차이가 10⁴ 배 이상log1p) 후에도 꼬리가 길어 모델 학습 시 분산이 과도하게 커짐4) 패킷 수 대칭성
# ==============================================================
# Cell 4-A ▸ 산점도 fwd vs bwd
# ==============================================================
plt.figure(figsize=(6,5))
sns.scatterplot(x=np.log1p(df["pkt_count_fwd"]), y=np.log1p(df["pkt_count_bwd"]),
hue=df["attack_type"], alpha=0.4, linewidth=0, s=12, legend=False)
plt.xlabel("log pkt_count_fwd"); plt.ylabel("log pkt_count_bwd")
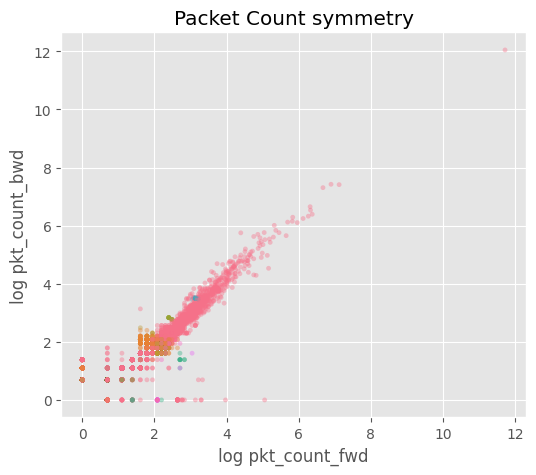
plt.title("Packet Count symmetry")
plt.show()
# ==============================================================
# Cell 4-B ▸ ratio 히스토그램
# ==============================================================
eps = 1e-6
df["pkt_ratio_fb"] = (df["pkt_count_fwd"]+eps)/(df["pkt_count_bwd"]+eps)
sns.histplot(np.log(df["pkt_ratio_fb"]), bins=100)
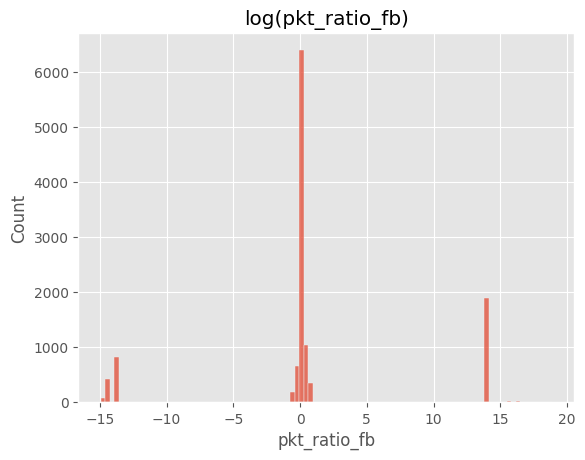
plt.title("log(pkt_ratio_fb)")
plt.show()
# ========================================================a======
# Cell 4-C ▸ 클래스별 평균·중앙값
# ==============================================================
stats_tbl = df.groupby("attack_type")[["pkt_ratio_fb"]].agg(["mean","median"]).round(2)
display(stats_tbl)
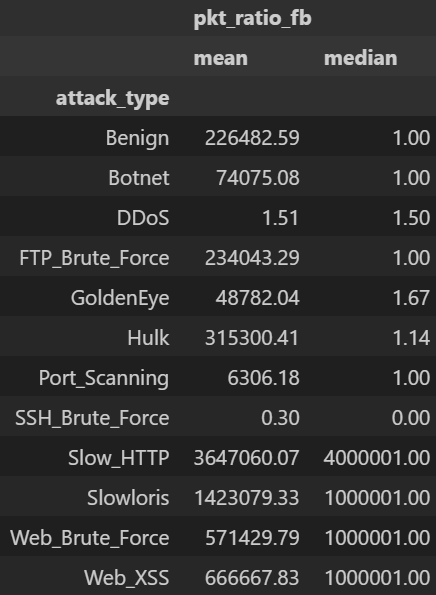
주요 인사이트
pkt_count_fwd, pkt_count_bwd)의 절대값 차이가 클래스별로 상이ratio≈1(양방향 균형),FTP_Brute_Force ratio≈∞ 패턴 존재.5) 전송률(rate) 로그 변환
# ==============================================================
# Cell 5-A ▸ rate_* 히스토그램 (linear vs log)
# ==============================================================
cols_rate = ["rate_fwd_pkts","rate_bwd_pkts","rate_fwd_bytes","rate_bwd_bytes"]
for col in cols_rate:
fig, ax = plt.subplots(1,2, figsize=(10,3))
sns.histplot(df[col].dropna(), bins=100, ax=ax[0]); ax[0].set_title(col)
sns.histplot(np.log1p(df[col].dropna()), bins=100, ax=ax[1]); ax[1].set_title(f"log1p {col}")
plt.tight_layout(); plt.show()
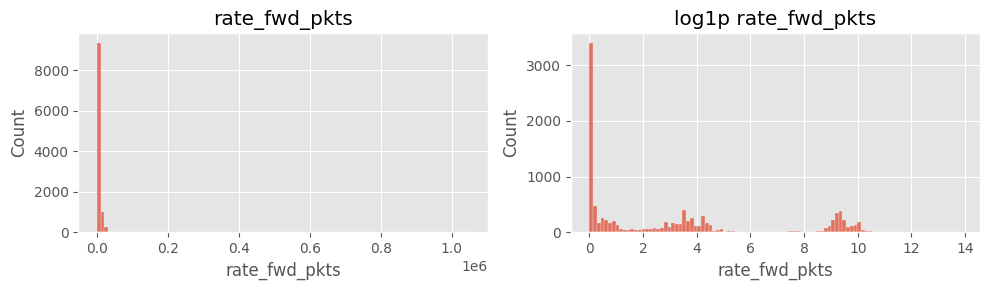
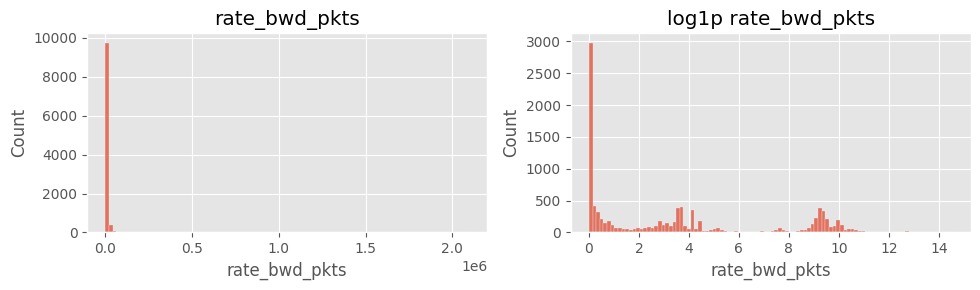
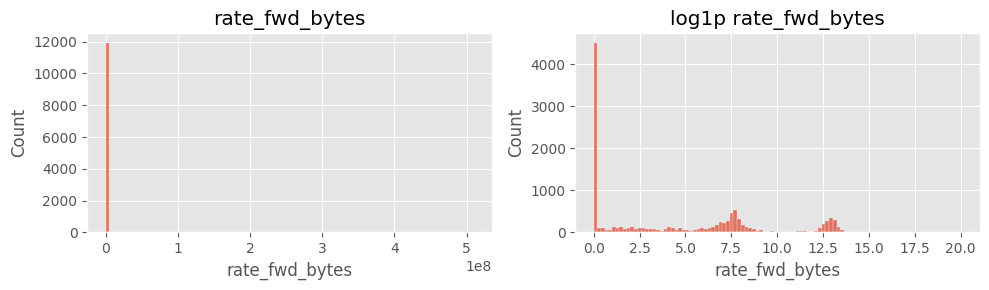
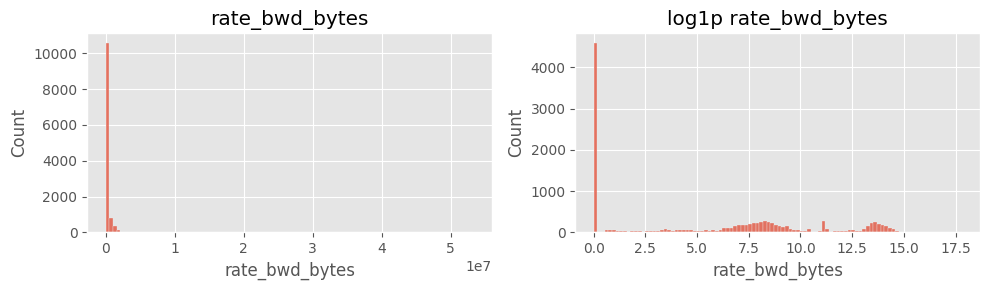
# ==============================================================
# Cell 5-B ▸ Scatter Matrix
# ==============================================================
from pandas.plotting import scatter_matrix
scatter_matrix(np.log1p(df[cols_rate]), figsize=(12,12), alpha=0.2)
plt.suptitle("Scatter Matrix – log(rate_*)")
plt.show()
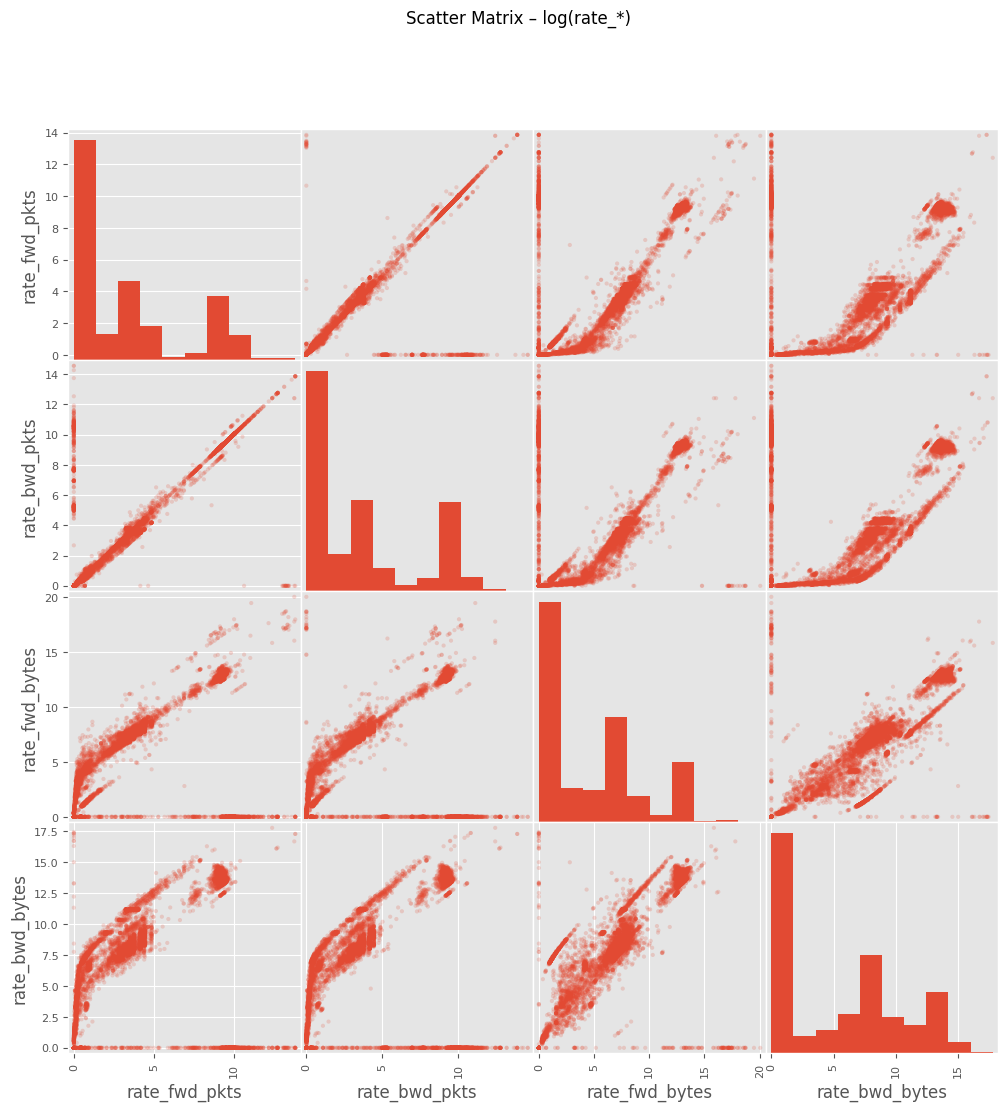
주요 인사이트
rate_fwd_bytes·rate_bwd_bytes 및 rate_fwd_pkts·rate_bwd_pkts 분포 극단적log1p 변환 후에도 꼬리 특성이 남음6) payload_*_mean 결측·0 구분
# ==============================================================
# Cell 6-A ▸ NaN vs 0 카운트
# ==============================================================
for col in ["payload_fwd_mean","payload_bwd_mean"]:
nan_cnt = df[col].isna().sum()
zero_cnt= (df[col]==0).sum()
print(f"{col}: NaN={nan_cnt}, zeros={zero_cnt}")
df["is_payload_missing"] = df["payload_fwd_mean"].isna() | df["payload_bwd_mean"].isna()
ct = pd.crosstab(df["is_payload_missing"], df["attack_type"], normalize="columns")*100
display(ct.style.format("{:.1f}%"))
payload_fwd_mean: NaN=1785, zeros=3837 payload_bwd_mean: NaN=1785, zeros=3837

주요 인사이트
payload_fwd_mean·payload_bwd_mean 에 10 % 안팎의 NaN 과, 실제 0 값이 공존7) tcp_win_*_init 프로토콜별 NaN 처리
# ==============================================================
# Cell 7-A ▸ 프로토콜별 tcp_win NaN 비율
# ==============================================================
for col in ["tcp_win_fwd_init","tcp_win_bwd_init"]:
pct = df.groupby("protocol")[col].apply(lambda s: s.isna().mean()*100)
print("\n", col); print(pct.round(1))
tcp_win_fwd_init protocol TCP 0.0 UDP 0.0 Name: tcp_win_fwd_init, dtype: float64 tcp_win_bwd_init protocol TCP 0.0 UDP 0.0 Name: tcp_win_bwd_init, dtype: float64
# ==============================================================
# Cell 7-B ▸ TCP 세션 히스토그램
# ==============================================================
tcp_df = df[df["protocol"]=="TCP"]
sns.histplot(tcp_df["tcp_win_fwd_init"].dropna(), bins=100)
plt.title("tcp_win_fwd_init (TCP only)")
plt.show()
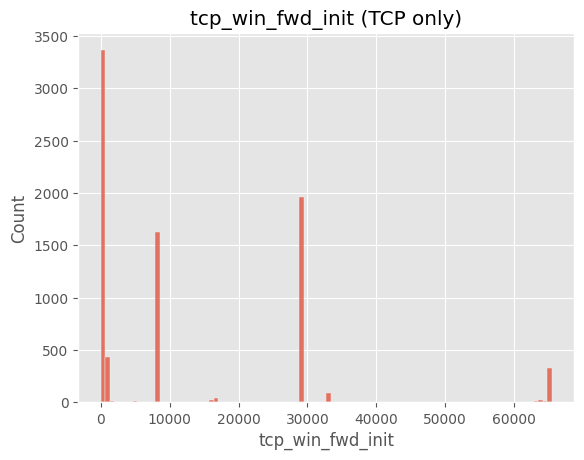
주요 인사이트
tcp_win_init 등) 컬럼은 특정 프로토콜(HTTP, TLS) 에만 정의되고 나머지는 NaN 값으로 존재.8) iat_avg_packets 로그 변환
# ==============================================================
# Cell 8-A ▸ IAT 히스토그램 선형 vs 로그
# ==============================================================
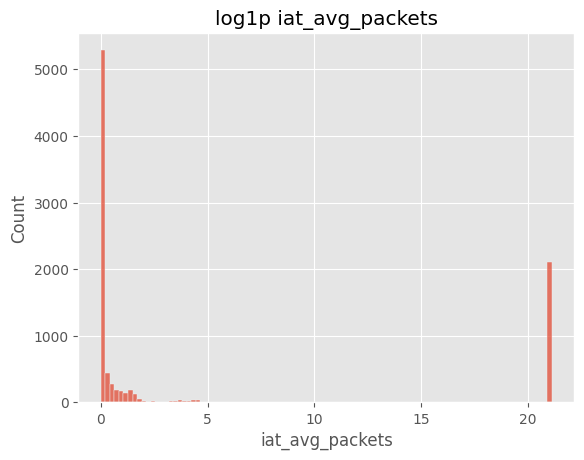
sns.histplot(df["iat_avg_packets"].dropna(), bins=100)
plt.title("iat_avg_packets (linear)")
plt.show()
sns.histplot(np.log1p(df["iat_avg_packets"].dropna()), bins=100)
plt.title("log1p iat_avg_packets")
plt.show()
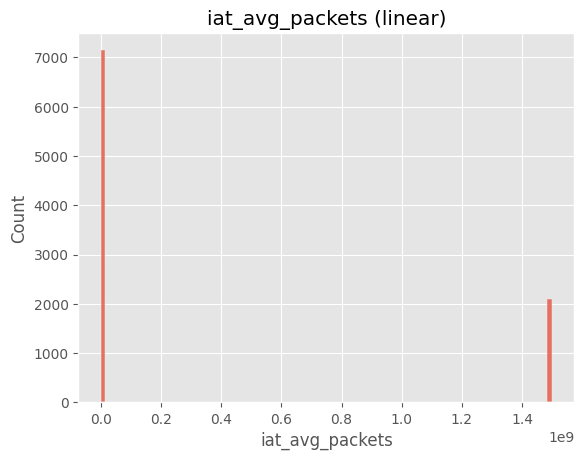
# ==============================================================
# Cell 8-B ▸ 클래스별 IAT 통계
# ==============================================================
iat_tbl = df.groupby("attack_type")["iat_avg_packets"].describe()[["mean","50%","min","max"]].round(3)
display(iat_tbl)
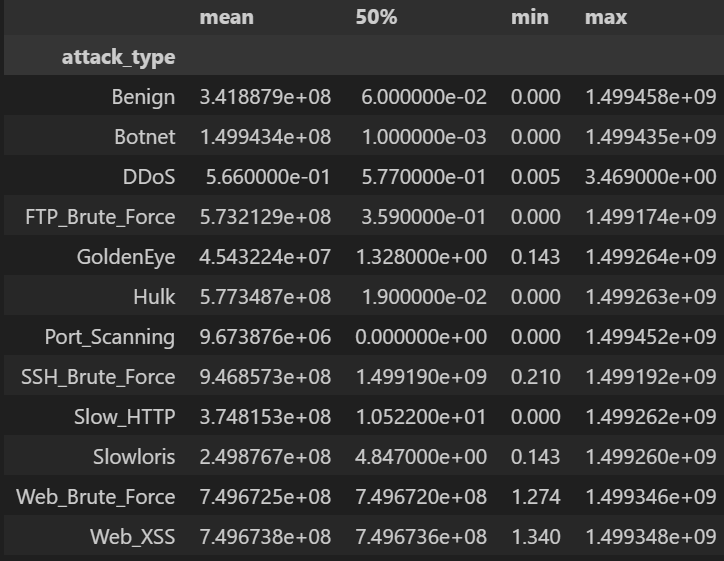
주요 인사이트
iat_avg_packets 로그 변환 후에도 Slow_HTTP, GoldenEye, Slowloris 등 느린 공격 탐지에 주요 지표로 활용될 수 있음.9) attack_type 불균형 정도
# ==============================================================
# Cell 9-A ▸ 클래스 BAR plot (이미 실행했지만 재확인)
# ==============================================================
cls_cnt = df["attack_type"].value_counts()
sns.barplot(x=cls_cnt.index, y=cls_cnt.values)
plt.xticks(rotation=45, ha="right")
plt.title("attack_type distribution")
plt.show()
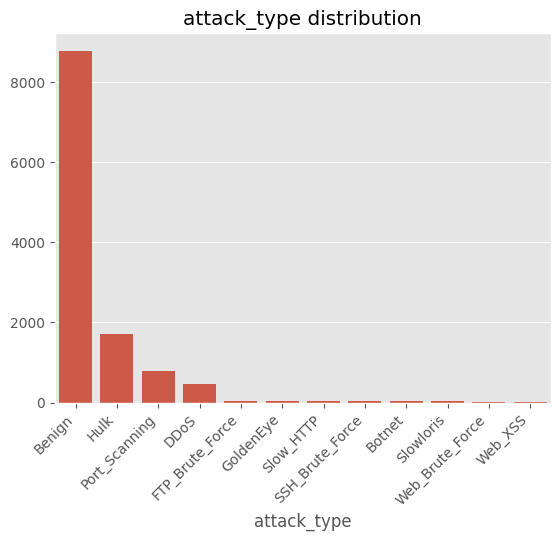
# ==============================================================
# Cell 9-B ▸ 주요 Feature 평균 Heatmap
# ==============================================================
feat_subset = ["duration","pkt_ratio_fb","rate_fwd_pkts","rate_bwd_pkts",
"payload_fwd_mean","payload_bwd_mean"]
heat = df.groupby("attack_type")[feat_subset].mean()
sns.heatmap(heat, annot=True, fmt=".1f", cmap="Blues")
plt.title("Mean feature values per class")
plt.show()
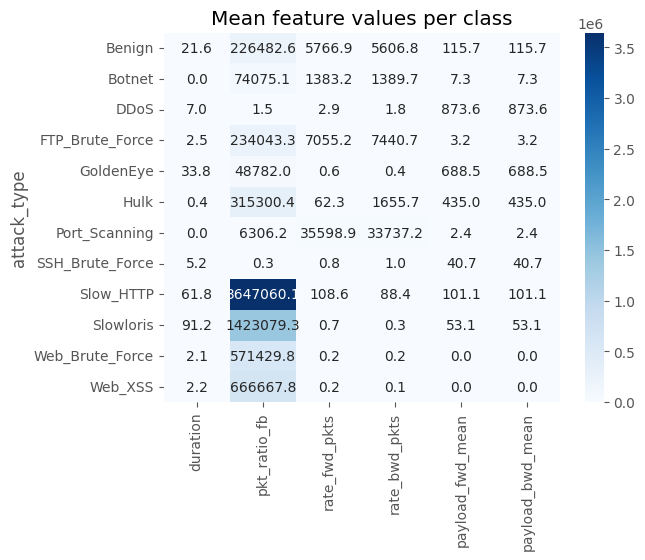
# ==============================================================
# Cell 9-C ▸ StratifiedKFold 후 클래스 분포
# ==============================================================
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)
for i, (_, val_idx) in enumerate(skf.split(df, df["attack_type"])):
fold_dist = df.loc[val_idx, "attack_type"].value_counts(normalize=True)*100
print(f"\nFold {i}:")
print(fold_dist.round(1))
Fold 0: attack_type Benign 73.3 Hulk 14.3 Port_Scanning 6.6 DDoS 4.0 FTP_Brute_Force 0.4 GoldenEye 0.3 Slow_HTTP 0.3 SSH_Brute_Force 0.2 Slowloris 0.2 Botnet 0.2 Web_Brute_Force 0.1 Web_XSS 0.0 Name: proportion, dtype: float64 Fold 1: attack_type Benign 73.2 Hulk 14.3 Port_Scanning 6.6 DDoS 3.9 FTP_Brute_Force 0.4 GoldenEye 0.3 Slow_HTTP 0.3 Slowloris 0.2 SSH_Brute_Force 0.2 Botnet 0.2 Web_XSS 0.1 Web_Brute_Force 0.1 Name: proportion, dtype: float64 Fold 2: attack_type Benign 73.2 Hulk 14.3 Port_Scanning 6.6 DDoS 3.9 FTP_Brute_Force 0.4 GoldenEye 0.3 Slow_HTTP 0.3 Botnet 0.2 SSH_Brute_Force 0.2 Slowloris 0.2 Web_Brute_Force 0.1 Web_XSS 0.0 Name: proportion, dtype: float64 Fold 3: attack_type Benign 73.2 Hulk 14.3 Port_Scanning 6.6 DDoS 3.9 FTP_Brute_Force 0.4 GoldenEye 0.4 SSH_Brute_Force 0.2 Botnet 0.2 Slow_HTTP 0.2 Slowloris 0.2 Web_Brute_Force 0.1 Web_XSS 0.0 Name: proportion, dtype: float64 Fold 4: attack_type Benign 73.3 Hulk 14.3 Port_Scanning 6.6 DDoS 3.9 FTP_Brute_Force 0.4 GoldenEye 0.3 Slow_HTTP 0.3 SSH_Brute_Force 0.3 Botnet 0.2 Slowloris 0.2 Web_Brute_Force 0.1 Web_XSS 0.0 Name: proportion, dtype: float64
데이콘(주) | 대표 김국진 | 699-81-01021
통신판매업 신고번호: 제 2021-서울영등포-1704호
직업정보제공사업 신고번호: J1204020250004
서울특별시 영등포구 은행로 3 익스콘벤처타워 901호
이메일 dacon@dacon.io |
전화번호: 070-4102-0545
Copyright ⓒ DACON Inc. All rights reserved
 목록으로
목록으로