

데이스쿨 할인 리턴즈
2025 Samsung Collegiate Programming Challenge : AI 챌린지
Baseline 모델에 대한 분석
안녕하세요! 이제 참가자 모집도 완료되었고, 1446명 저희들이 남았네요! 주말에도 다들 화이팅입니다! 최근 InstructBLIP 논문을 읽다 재미있는 글귀를 읽어 토크에 공유드립니다.
결론: 저희 task에 baseline으로 blip-2 opt보다는 blip-2 Flan T5가 더 적절한 것 같습니다.
근거는 아래와 같습니다.
InstructBLIP 논문: subsection 3.5 Finetuning InstructBLIP on Downstream Tasks
"Additionally, we observe that the FlanT5-based InstructBLIP is superior at multi-choice tasks, whereas Vicuna-based InstructBLIP is generally better at open-ended generation tasks. This disparity can be primarily attributed to the capabilities of their frozen LLMs, as they both employ the same image encoder. Although FlanT5 and Vicuna are both instruction-tuned LLMs, their instruction data significantly differ. FlanT5 is mainly finetuned on NLP benchmarks containing many multi-choice QA and classification datasets, while Vicuna is finetuned on open-ended instruction-following data."
요약하자면, " BLIP계열 모델에서 Flan T5 (encoder-decoder based LLM)이 Vicuna (decoder only)보다 multi-choice tasks에 더 적적하다"
추가로 BLIP2** 논문을 읽으면 encoder-decoder(Flan T5) LLM과 decoder only (OPT) LLM에 대한 내용이 있습니다.
BLIP2 논문: subsection 3.3. Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
BLIP2논문: Figure3
We experiment with two types of LLMs: decoder-based LLMs and encoder-decoder-based LLMs. For decoderbased LLMs, we pre-train with the language modeling loss, where the frozen LLM is tasked to generate the text conditioned on the visual representation from Q-Former. For encoder-decoder-based LLMs, we pre-train with the prefix language modeling loss, where we split a text into two parts. The prefix text is concatenated with the visual representation as input to the LLM’s encoder. The suffix text is used as the generation target for the LLM’s decoder.
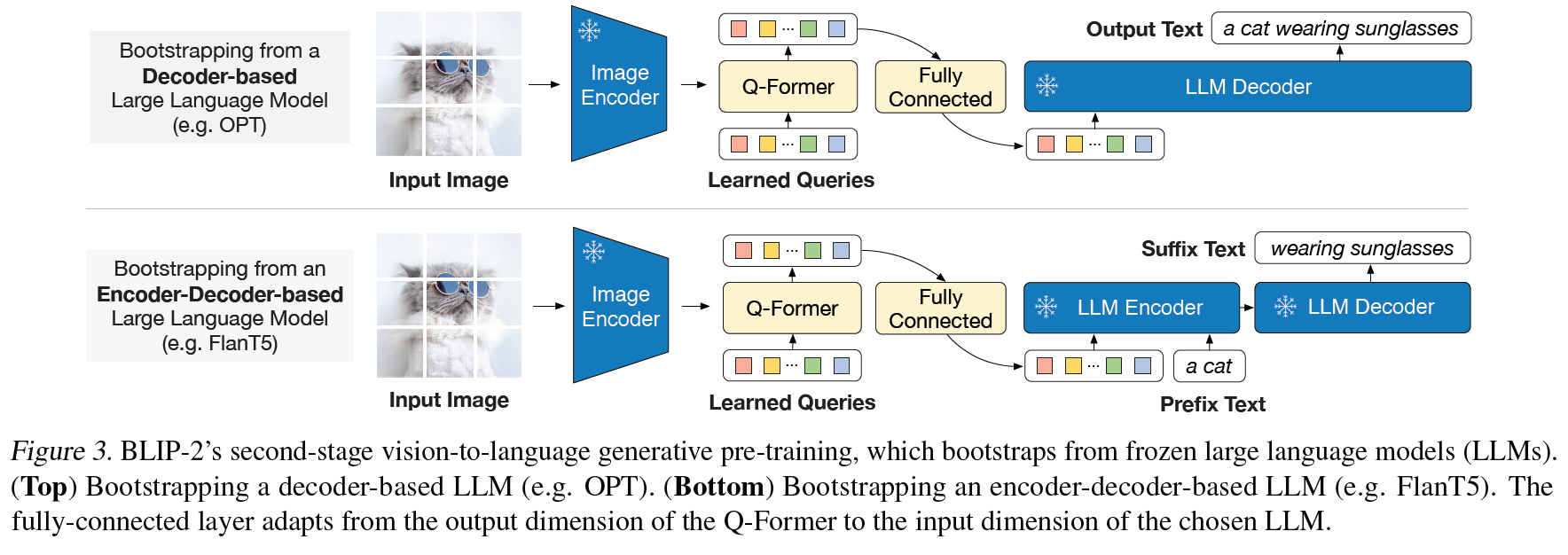
본문과 그림에서 OPT는 decoder-based LLM이고, Flan T5는 encoder-decoder-based LLM 라고 언급합니다.
다들 이번 기회에 멀티모달에 대해 많은 공부가 되었으면 좋겠습니다! ^^
* Dai, Wenliang, et al. "Instructblip: Towards general-purpose vision-language models with instruction tuning." Advances in neural information processing systems 36 (2023): 49250-49267.
** Li, Junnan, et al. "Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models." International conference on machine learning. PMLR, 2023.
데이콘(주) | 대표 김국진 | 699-81-01021
통신판매업 신고번호: 제 2021-서울영등포-1704호
직업정보제공사업 신고번호: J1204020250004
서울특별시 영등포구 은행로 3 익스콘벤처타워 901호
이메일 dacon@dacon.io |
전화번호: 070-4102-0545
Copyright ⓒ DACON Inc. All rights reserved
 목록으로
목록으로