

DASCHOOL 할인 리턴즈
토스 NEXT ML CHALLENGE : 광고 클릭 예측(CTR) 모델 개발
private 2등 솔루션 공유
최종 보고서를 gpt로 문체를 바꾼 뒤 공유드립니다.
데이콘이 처음이라 보고서를 word형식으로 만들었는데, ppt형식으로 만들어야 하나 보네요...
이름이 지정된 5개 주요 feature에 대해 count와 target ratio를 분석한 결과, categorical로 분류했습니다.
해당 feature는 gender, age_group, inventory_id, day_of_week, hour이며, numerical feature에 비해 값별 모수 및 타겟 비율의 차이가 컸고, 고유값(nunique) 수도 낮았습니다.
hour feature는 주기적 분포(cyclical pattern)가 확인되어 **cyclical encoding(sin/cos)**을 적용했습니다.
반면 day_of_week는 주기성을 가지지만 요일별 차이가 커서 주말/평일 구분 효과로 판단했습니다. Cyclical encoding을 적용했을 때 오히려 성능이 하락해 최종적으로 제외했습니다.
Categorical로 구분된 5개 feature를 제외한 나머지 feature는 연속적 분포를 보였고, target과 선형적인 관계를 보여 numerical로 취급했습니다.
일부 nunique ≤ 100인 feature를 categorical로 변환해보았지만, overfitting이 심해져 제외했습니다.
데이터 내 null 값들이 특정 feature 단위로 block 형태로 발생했습니다.
이를 세 개의 그룹으로 구분하고 각 그룹의 null 여부를 categorical feature로 추가했습니다.
대표 feature는 gender, feat_a_1, feat_e_3를 사용했습니다.
Numerical Feature 처리:
결측값은 median으로 대체해 long-tail 분포를 보정하고 안정적인 성능을 확보했습니다.
이후 StandardScaler를 적용해 정규화했습니다.
Median 처리한 값과 StandardScaler 처리한 값을 동시에 feature로 사용했습니다.
Categorical Feature 처리:
Label Encoding 후 astype(‘category’) 변환을 수행했습니다.
Null 값은 -999999999로 치환 후 변환했고, Count Encoding과 np.log1p를 적용해 빈도수를 정규화했습니다.
또한 Frequency Encoding도 함께 적용했습니다.
각 sequence 원소에 대해 value_counts를 계산한 뒤 np.log1p 변환을 적용했습니다.
Train에서 관측된 원소만 사용하고, train에는 있으나 valid/test에는 없는 항목은 0으로 대체했습니다.
Sequence 길이(len)와 고유 원소 개수(nunique)에도 각각 np.log1p를 적용했으며, nunique/length 비율 feature도 추가했습니다.
Sequence feature는 각 row 단위로 계산되므로 전체 train 데이터에 대해 한 번 학습 후 transform했습니다.
Non-sequence feature는 fold별 train 데이터에서만 fit하여 OOF-safe하게 처리했습니다.
StratifiedKFold를 적용해 3개의 Fold-Set과 5개의 Fold 구조로 학습했습니다.
Stratify는 target에만 적용했습니다.
10fold 실험도 수행했으나, 시간 대비 성능 향상이 미미했고 fold별 validation 예측 분산이 커서 5-Fold로 확정했습니다.
모델의 안정성을 확보하기 위해 seed=[0, 42, 100]을 사용했습니다.
Fold-Set Seed와 Model Seed를 모두 다양화하여 일반화 성능을 높였습니다.
Optuna를 활용해 약 20~40회 iteration을 수행했습니다.
LGBMClassifier의 경우 GPU 학습 시 일부 파라미터 조합에서 학습이 불안정했기 때문에, CPU 학습으로 전환해 안정성을 확보했습니다.
주요 모델은 **LightGBMClassifier(AUC metric)**을 사용했습니다.
CatBoost와 XGBoost도 실험했지만, Ensemble 시 LightGBM 단독 모델이 가장 높은 리더보드 성능을 보였습니다.
Weighted Log Loss(WLL)이 class imbalance에 민감하므로, class_weight=‘balanced’를 적용했습니다.
각 모델의 validation 예측 확률(proba)을 이용해 Greedy Ensemble을 수행했습니다.
기존 예측에 추가했을 때 성능이 가장 개선되는 모델을 선택하고, 가중치 k를 0.01~1.0 범위에서 탐색했습니다.
성능 향상이 없을 때까지 반복 수행했습니다.
Hill Climbing으로 얻은 최종 예측 확률을 Logistic Regression으로 재보정했습니다.
확률을 Logit 변환 후 Logistic Regression을 적용했고, Average Precision(AP)을 유지하면서 Weighted Log Loss(WLL)을 개선하는 방향으로 학습했습니다.
Metric은 ‘neg_log_loss’를 사용했습니다.
최종적으로 CV 기준 스코어는 0.357666 → 0.357916, WLL은 0.5916 → 0.5903으로 개선되었습니다.
초기에는 QuantileTransformer를 사용했습니다.
이 경우 feature 간 거리 정보가 손실되어 이를 보정하기 위해 원본 feature를 함께 사용했습니다.
이와 유사한 방식은 Kaggle 등에서도 종종 사용됩니다.
이후 StandardScaler로 변경하면서 원본 feature가 제거된 줄 알았지만, 검증 과정에서 남아 있음을 발견했습니다.
성능에 큰 문제는 없었지만, 중복으로 인해 weight가 늘어날 수 있으므로 개선 여지는 남았습니다.
단일 모델 구조에서도 Fold Seed와 Model Seed를 다양화하면 리더보드 점수 변동 폭이 줄어들고 CV-LB 일관성이 개선되었습니다.
Seed를 2→3으로 늘렸을 때도 시간 대비 효율이 높다고 판단해 채택했습니다.
class_weight=‘balanced’를 설정하면 WLL 성능이 안정적으로 향상했습니다.
대부분의 모델은 Logloss보다 AUC 기준 학습 시 학습 시간 단축 및 성능 향상이 있었습니다.
Logloss 학습은 확률 보정에는 유리하지만 rank 성능은 낮았습니다.
CatBoost는 Logloss 기반 학습 시 단일 모델 성능은 높았지만, Ensemble에서는 AUC 기반 모델이 더 좋은 성능을 보였습니다.
최종 Calibration 단계에서는 AP를 유지하면서 WLL을 감소시키는 방향으로 Logistic Regression 기반 보정을 적용했습니다.
초기에는 Ensemble 자체를 Logistic Regression으로 수행해 WLL을 개선했습니다.
하지만 다양한 모델 조합에서는 오히려 성능이 저하되었습니다.
이는 모델 간 확률 스케일 차이와 Fold 간 분포 차이로 인한 overfitting이 원인으로 추정됩니다.
Calibration 관점에서 Logistic Regression은 WLL 개선에 실질적인 효과를 보였으며,
Calibration 기법으로 활용 가능성을 입증했습니다.
다양한 조합을 실험한 결과, 최종적으로 Hill Climbing으로 Ensemble을 수행한 뒤 Calibration을 적용하는 방법이 가장 안정적이었습니다.
이 모델은 Public 기준 7위였지만 Private 기준 1위를 기록했습니다.
데이터 수집 단계에서 value_counts 형태({token_id: count})로 저장하면 문자열 파싱과 변환 과정을 생략할 수 있습니다.
이를 통해 전처리 시간을 단축하고 메모리 사용량과 I/O 부담을 줄일 수 있습니다.
대회에서는 CV–LB 간 차이를 최소화하기 위해 다중 seed 기반 OOF-safe 전처리를 적용했습니다.
하지만 실제 운영 환경에서는 전체 데이터를 기반으로 통계 추정 후 단일 변환을 적용해도 성능 저하는 크지 않을 것으로 예상됩니다.
이를 통해 파이프라인을 단순화하고 추론 속도를 높일 수 있습니다.
Fold-Set, Fold, Model 단위로 병렬 추론을 수행하면 추론 시간을 단축할 수 있습니다.
이 방식은 대규모 환경에서 latency 관리에도 유리합니다.
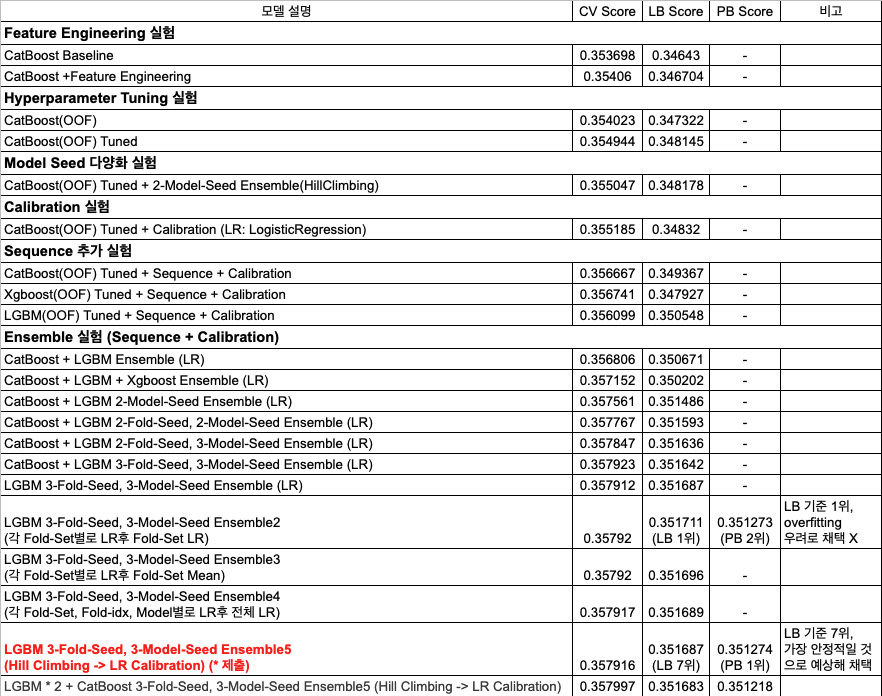
실험은 catboost로 계속 진행하면서 xgboost, lgbm도 추가로 학습했고, 앙상블 단계에서 lgbm만 사용하는게 제일 잘 나와서 lgbm만 사용했습니다.
3 foldset × 3seed로 9개의 lgbm 5fold가 최종 결과물입니다.
DACON Co.,Ltd | CEO Kookjin Kim | 699-81-01021
Mail-order-sales Registration Number: 2021-서울영등포-1704
Business Providing Employment Information Number: J1204020250004
#901, Eunhaeng-ro 3, Yeongdeungpo-gu, Seoul 07237
E-mail dacon@dacon.io |
Tel. 070-4102-0545
Copyright ⓒ DACON Inc. All rights reserved
 List
List
저희 또한 논문 형식에 맞추어 작성하였습니다. 자율 형식이라 큰 제약은 없을 것 같습니다.
모델은 LightGBM 단일 구조를 사용하신 건가요? 저희도 초기에 시도했으나 성능이 기대에 미치지 못해 다른 모델을 채택했는데,
모델링 접근 방식의 차이가 원인일 수도 있겠네요. 혹시라도 코드를 올리시게 된다면 많이 배우도록 하겠습니다!