

데이스쿨 할인 리턴즈
머신러닝 기초 트랙 질문
질문1.
데이콘 3기 머신러닝 기초 트랙 <머신러닝과 데이터 전처리 기초>에서 스테이지 2에 나온 내용 질문 드립니다.
첨부한 사진 좌측 "결과해석"에 보면 "서로 동일한 정보를 가진 중복 행이 세 개 존재한다"라고 하는데
우측에 출력된 결과에서 인덱스 419, 716, 877이 지들 3개끼리 서로 중복된다는 건가요?
그렇다기엔 인덱스(행)별로 내용들을 봤을때 몇개 열에서는 내용이 3개 모두 동일하게 중복되지만 전체 데이터는 상당 부분 다른데요.
아니면 전체 수백개 되는 train 데이터 프레임 내에서
인덱스 419와 겹치는 행이 몇개 있고, 716과 겹치는 행이 몇개 있고, 877과 겹치는 행이 몇개 있는 건가요?
"결과해석"을 어떻게 이해하면 될지 여쭤보고싶어요.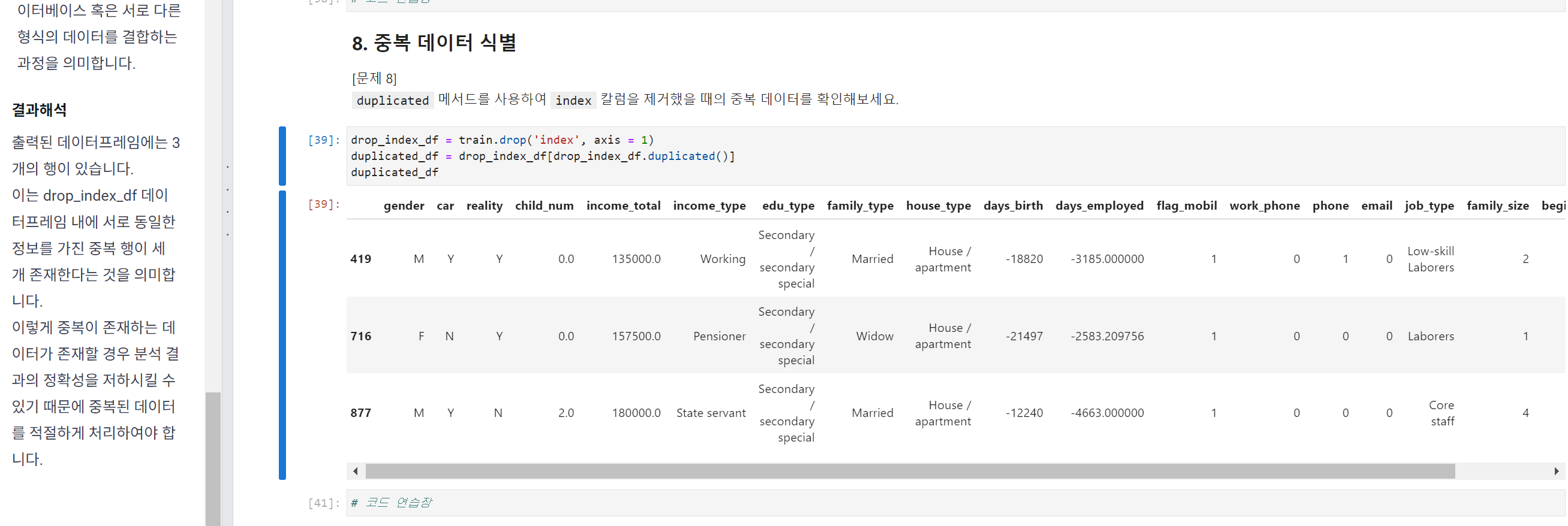
질문2. 트랙 페이지에 있는 저 학습 타이머는 뭔가요? 시간이 줄어들던데 저 시간이 끝나면 수강이 불가능한건가요?
질문3. 강의 자료를 받아볼 수 있는 법은 없나요?
데이콘(주) | 대표 김국진 | 699-81-01021
통신판매업 신고번호: 제 2021-서울영등포-1704호
직업정보제공사업 신고번호: J1204020250004
서울특별시 영등포구 은행로 3 익스콘벤처타워 901호
이메일 dacon@dacon.io |
전화번호: 070-4102-0545
Copyright ⓒ DACON Inc. All rights reserved
 목록으로
목록으로
LAGB 님. 안녕하세요
질문1. 앞의 코드를 모두 실행한 다음 스텝 8에서의 코드를 아래 코드로 대체해주세요.
```
import pandas as pd
# 'index' 열을 제외하고 중복된 행을 찾기
drop_index_df = train.drop('index', axis=1)
duplicated_df = drop_index_df[drop_index_df.duplicated()]
# 특정 인덱스의 행을 확인
example_index = 419
example_row = drop_index_df.iloc[example_index]
# example_row와 동일한 데이터를 가진 행들을 찾기
is_duplicated = drop_index_df.apply(lambda row: row.equals(example_row), axis=1)
duplicated_indices = is_duplicated[is_duplicated].index
display(train.iloc[duplicated_indices])
```
위 코드는 중복이 있는 데이터프레임을 확인하여 값이 동일한 데이터프레임을 출력하는 코드입니다.(인덱스 제외)
duplicated_df를 출력하면 419, 716, 877 인덱스를 가진 행에서 중복이 확인됩니다.
코드의 실행 결과를 보았을 때 324, 419 인덱스의 데이터가 동일합니다.
example_index 의 값을 각각 바꿔보면 중복된 값이 2개씩 존재하는 것으로 확인됩니다.
따라서 419, 716, 877 인덱스와 동일한 데이터를 가지는 데이터가 1개씩 더 존재한다는 의미를 8번 스텝에서 담고있습니다.(인덱스 제외)
질문2. 트랙 종료일까지를 타이머로 나타낸 것으로, 24일 3시간 36분 후에 트랙이 종료되는 것을 의미합니다.
감사합니다.